There’s a word that’s been sitting in my head lately and I think it’s the right one.
Not developer. Not user. Not prompt engineer — please, not that.
Operator.
The developer builds the system. The user benefits from it. The operator runs it.
Operators have always existed. They’re the people who know a tool well enough to get unusual things out of it — who understand what’s possible, who can configure and connect and troubleshoot, who treat software as infrastructure rather than a product to consume. In a restaurant, the chef is the operator. In a warehouse, it’s the floor manager who actually knows where everything is and why the inventory system does what it does.
In most software companies, the operator was assumed to be technical. You needed to code, or at least to read code, to run anything at a real level of depth. Everyone else was a user — handed a finished product, expected to stay in the designated lanes.
That line is moving.
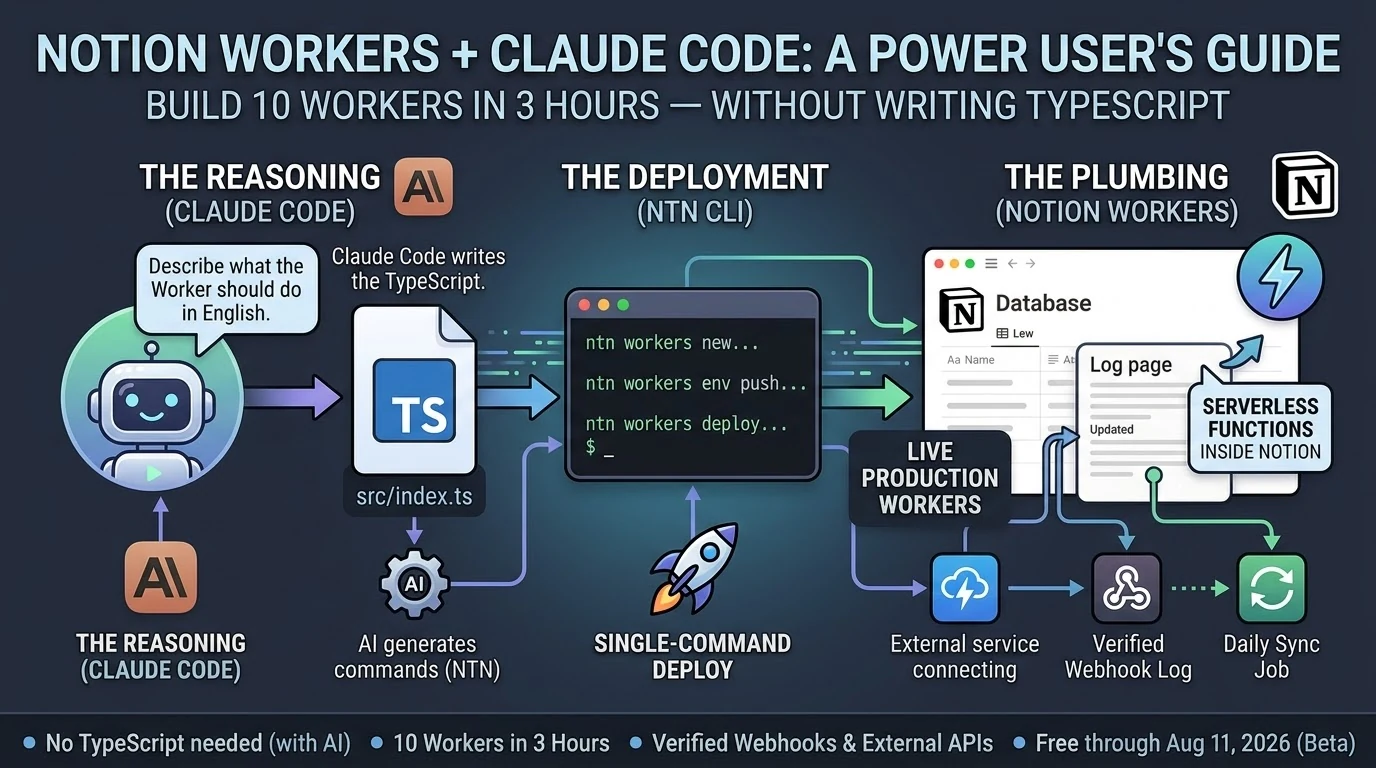
Last night I deployed ten Notion Workers in three hours. Workers are Notion’s new hosted serverless platform — real code, running inside Notion’s infrastructure, no server to manage. I built a webhook endpoint that receives authenticated HTTP traffic from the internet and logs it to a Notion database. I built data sync Workers. I built scheduled jobs.
I am not a developer.
What I am is an operator. I know what I want the system to do. I can describe it precisely. I understand how the pieces connect even when I can’t write the connection myself. And I have Claude Code, which handles the TypeScript while I handle the architecture.
The stack looks like this:
Claude Code — the reasoning layer. Describe what the Worker should do in plain English. Claude Code writes the code, catches errors when you paste them back, and tells you exactly what commands to run.
ntn CLI — the deployment layer. Four commands: scaffold, write, push secrets, deploy. Single-command deploys. You run what Claude Code tells you to run.
Notion Workers — the execution layer. Serverless functions running on Notion’s infrastructure. They connect to external APIs, respond to webhooks, sync data, run on schedules. They do the work while you do something else.
That’s it. Three layers. None of them require you to be a developer to operate.
The operator’s job in this stack is not to write code. It’s to know what should exist.
That sounds simple. It isn’t. Knowing what should exist means understanding your own operations well enough to identify where the friction is, what’s being done by hand that shouldn’t be, what would run better automatically. It means being able to describe a system clearly enough that an AI coding agent can build it. It means reviewing what gets built and knowing whether it’s right.
That’s real skill. It’s just not the skill most people thought they needed.
For years the implicit message was: if you can’t build it, you can’t have it. The work of describing exactly what you want, of thinking through the logic, of understanding how systems connect — that work was treated as a prerequisite for coding, not a valuable thing in its own right.
Now it’s the job.
I’m not going to tell you the technical barrier is gone. It isn’t. You still hit errors. You still have to read them and understand them well enough to know if Claude Code’s fix makes sense. You still have to think before you build.
But the barrier has moved. The question is no longer “can you write TypeScript” — it’s “can you think clearly about what you want and describe it precisely.”
Most people reading this can do that. They’ve been able to do that. They were just told, implicitly or explicitly, that it wasn’t enough.
It’s enough now.
The Notion Workers beta is free through August 11, 2026. The ntn CLI installs in one line on macOS or Linux. Deploying Workers requires a Business or Enterprise plan. If you’ve been running your operations in Notion and watching things like Workers from the sidelines because you figured it was for developers: it’s for operators too. You might already be one.
It was late. I had Claude Code open on my laptop and a fresh cup of coffee going cold next to it.
Notion had shipped Workers eight days earlier — their new hosted serverless platform, basically “run real code inside Notion without managing a server.” I’d been meaning to dig in. Last night I finally did.
I want to tell you what that actually looked like. Not a tutorial. Not a polished case study. Just what happened, in order, including the parts that didn’t work.
By midnight I had ten Workers deployed and a live webhook endpoint logging authenticated traffic from the internet into a Notion page. The whole thing took about three hours.
I did not write TypeScript.
Here’s the honest version of how it went.
The first Worker took the longest — maybe 35 minutes — because I was figuring out the CLI at the same time as building the thing. The ntn tool is straightforward once you understand it: scaffold, write the code, push your secrets, deploy. Four steps. But the first time through any new tool you’re reading error messages and second-guessing yourself.
Claude Code handled the TypeScript. I described what I wanted — a Worker that receives a POST request, verifies an HMAC signature, and appends a line to a Notion log page. Claude Code wrote it. I ran the commands it told me to run. The Worker deployed.
I tested it. It worked.
The second one took 22 minutes. The third took 15. By Worker five I was moving fast enough that I stopped tracking individual times and just kept going.
Two of them didn’t work on the first try. One had a secret I’d named wrong in the environment — my fault, five minutes to fix. The other had a logic error in how it was handling the Notion API response. Claude Code caught it when I pasted the error back in, rewrote the relevant section, and I redeployed. Eight minutes total for that dead-end.
Neither failure felt like a crisis. That’s the part I want to underline. When something broke, the path forward was obvious: read the error, paste it back to Claude Code, get a fix, redeploy. The loop was tight enough that failure was just a speed bump, not a wall.
At 02:54 in the morning, I sent a test ping to Worker #8.
The webhook logger received it, verified the HMAC signature, and wrote this to a Notion page in real time:
🔔 2026-05-21T02:54:44.452Z [claude-test:test] {"event":"test","message":"Hello from Worker #8 self-test","sender":"claude-code"}
I sat there for a second looking at that.
There’s something specific about seeing a system you built actually receive traffic. It’s not the same as a script running on your laptop. This was a deployed endpoint, on Notion’s infrastructure, receiving an authenticated HTTP request from the open internet and writing the result to a database. Automatically. Without me doing anything after the initial deploy.
That’s a different category of thing than what I had before.
I want to be honest about what I am, technically. I’m not a developer. I’ve picked up enough over the years to be dangerous — I can read code, I understand how APIs work, I’ve shipped things — but I’m not someone who sits down and writes TypeScript from scratch.
Last night didn’t require that. What it required was knowing what I wanted, being able to describe it clearly, and being willing to run commands and read errors.
That’s it.
The question I keep hearing from people who run operations like mine — agencies, small teams, people who live in tools like Notion and have always hired out the code work — is whether any of this AI coding stuff is actually for them or if it’s still fundamentally a developer story with a better interface.
Last night felt like an answer. Ten Workers. Three hours. No TypeScript.
If you can describe what you want clearly enough to explain it to another person, you can build this. The friction that used to live between “I know what I want” and “it exists in the world” is genuinely smaller now.
Not gone. Smaller.
You still have to show up. You still have to read the errors. You still have to think through what you’re building before you build it.
But if you’ve been waiting for some invisible threshold of technical credibility before you try — you’re past it. You were probably past it a while ago.
The Notion Workers beta is free through August 11, 2026. The ntn CLI installs in one line. Business or Enterprise plan required to deploy.
Notion shipped Workers on May 13, 2026. By last night I had ten of them running in production, including a live HMAC-verified webhook endpoint that’s actively logging events. Total build time: about three hours.
I didn’t write TypeScript by hand. Claude Code did most of the typing.
Here’s what that actually looked like — and what it means for the non-developer Notion power user who’s been watching the Workers announcement and wondering if it’s for them.
What are Notion Workers? Notion Workers are hosted serverless functions that run inside Notion’s infrastructure. You write code, deploy it through the ntn CLI, and Notion runs it in a secure sandbox — no server to manage. They’re free through August 11, 2026, then run on Notion credits. Deploying Workers requires a Business or Enterprise plan.
What Notion Workers Actually Are (The One-Paragraph Version)
If you’ve used Notion’s built-in database automations — the lightning bolt icon — Workers are that concept extended to real code. They can call any external API, respond to webhooks, sync data from Stripe or Zendesk or GitHub, and write results back to Notion databases. The CLI (ntn) is available on all plans. Deploying Workers requires Business or Enterprise.
Do You Need to Know TypeScript to Build Notion Workers?
Technically, Workers are written in TypeScript. Practically, if you have Claude Code, the answer is no.
Claude Code (currently at v2.1.144 as of May 19, 2026) scaffolds Workers from plain-English descriptions. You describe what the Worker should do. Claude Code writes the src/index.ts, handles the ntn workers env push for secrets, and tells you exactly what commands to run. You copy the command. The Worker deploys.
The workflow looks like this:
ntn workers new my-worker-name — scaffold the project
ntn workers deploy --name my-worker-name — ship it
That’s it. The only thing you actually type is the deploy commands. Claude Code fills in the gap between them.
What We Built in 3 Hours
Ten Workers, averaging about 18 minutes each, including two dead-ends that took 5–8 minutes to diagnose and abandon.
The most useful one is Worker #8: an HMAC-verified webhook logger. Any external service — GitHub, Stripe, a cron trigger, another Claude Code session — can POST to the Worker’s endpoint with a shared secret, and it auto-appends a timestamped line to a Notion log page. The webhook log shows its first self-test ping from Claude Code at 02:54 UTC:
🔔 2026-05-21T02:54:44.452Z [claude-test:test] {"event":"test","message":"Hello from Worker #8 self-test","sender":"claude-code"}
That’s a live, verifiable event log. Not a draft. Not a mock. A deployed Worker receiving authenticated HTTP traffic and writing to Notion.
The ntn workers env push command works cleanly for both NOTION_API_TOKEN and non-Notion secrets like TYGART_WP_USER and WEBHOOK_SECRET — one of the key things we needed to confirm before trusting the stack at scale.
The Design Principle That Makes This Actually Work
The best insight from Notion’s Workers documentation: use code for deterministic work, use AI for judgment calls.
A Worker that pulls invoice status from Stripe and updates a Notion database doesn’t need AI. It needs reliable, cheap code execution. That’s what Workers give you. A Claude Sonnet 4.6 (claude-sonnet-4-6) or Opus 4.7 (claude-opus-4-7) agent that reads those Notion rows and drafts follow-up emails is handling the judgment call. Those are two different tools for two different jobs.
When you collapse that distinction — letting AI do everything — you pay AI prices for work that shouldn’t require AI reasoning. Workers run at a fraction of the cost of AI credits. Notion’s own example calculations put a daily sync job at roughly one cent per month. The AI layer sits on top for the parts that actually need it.
This is the architecture: Workers handle the plumbing. Claude handles the reasoning. You stop paying Opus rates for jobs a ten-line TypeScript function can do.
The Part Nobody Else Is Writing About
Every guide covering Notion Workers frames it as a solo-developer workflow. You sit down, you know TypeScript, you build a Worker over an afternoon.
That’s not how this went.
Claude Code is listed in Notion’s own documentation as a first-class deployment partner for Workers. The ntn CLI was explicitly designed to work with coding agents — same interface for humans and agents. When you treat Claude Code as the author and yourself as the operator running the commands it outputs, you get through ten Workers in a session that most developers would take a week to plan.
The non-developer angle is real. If you run Notion as your operating system — databases, automations, dashboards — and you’ve been watching the Workers announcement wondering whether it requires a CS degree, the answer in May 2026 is: not if you have Claude Code. The scaffolding is a one-line command. The deployment is a one-line command. Claude Code fills in the gap between them.
Three Things to Know Before You Start
Business or Enterprise plan required to deploy. The CLI (ntn) installs on any plan and runs free. Deploying Workers needs Business or Enterprise. Check your plan before you spend an afternoon scaffolding.
macOS and Linux only as of May 2026. Windows users need WSL2. Native Windows support is listed as coming soon. If you’re on Windows without WSL2, that’s your first step.
Free through August 11, 2026. After that, Workers run on Notion credits. Build and optimize now while the cost is zero. The free period gives you enough runway to understand your actual usage patterns before you’re paying for them.
Frequently Asked Questions
What is the Notion Workers free period?
Notion Workers are free to try during the beta period, which runs through August 11, 2026. After that date, Workers will run on Notion credits. The free period is a good window to build, test, and optimize your Workers before metered usage begins.
Can non-developers build Notion Workers?
Yes, if you have an AI coding agent like Claude Code. Workers are written in TypeScript, but Claude Code can generate the Worker code from a plain-English description. You run the scaffold and deploy commands; Claude Code writes the code. No prior TypeScript knowledge required.
What Notion plan do you need for Workers?
The ntn CLI is available on all Notion plans. Deploying and managing Workers requires a Business or Enterprise plan.
How does Claude Code work with Notion Workers?
Claude Code (v2.1.144 as of May 2026) integrates directly with the ntn CLI. Notion designed the CLI as a tool for both humans and coding agents — same interface, same commands. Claude Code scaffolds the Worker TypeScript, sets environment variables, and outputs the exact deploy commands to run.
What can Notion Workers do?
Workers can call any external API, respond to incoming webhooks (with HMAC verification), sync data between external services and Notion databases, run scheduled tasks, and execute custom business logic. Common use cases include syncing Stripe payments, Zendesk tickets, GitHub issues, or any service with an API into Notion.
Is the ntn CLI available on Windows?
As of May 2026, the ntn CLI is available on macOS and Linux. Windows support is listed as coming soon. Windows users can use WSL2 in the meantime.
The Bottom Line
Ten Workers. Three hours. A verified webhook endpoint logging live traffic. Claude Code did the TypeScript. The ntn CLI did the deployment. Notion’s infrastructure handled everything else.
The question isn’t whether Notion Workers are for developers. The question is whether you have a coding agent. If you do, the friction is gone.
Most engineers who install MCP servers in Claude Code stop at GitHub. That’s a mistake. The GitHub server is the easy first install — but the integration that actually changes how I work is Sentry, and the pattern that emerges once it’s wired up tells you everything about how to think about MCP.
Here’s the workflow I’m running this week: an alert fires in Sentry, I paste the issue ID into Claude Code, and the agent reads the stack trace, pulls the offending file from the repo, writes the fix, opens a PR, and links the PR back to the Sentry issue. I never opened the Sentry dashboard. I never copy-pasted a stack trace. Two MCP servers, one terminal, one round trip.
Why Sentry is the high-value second install
GitHub MCP makes Claude Code a contributor. Sentry MCP makes it an on-call responder. The difference matters because the most expensive minutes in any engineering org are the ones between “alert” and “first line of investigation.” That gap is almost entirely context-switching cost — tab to the alerting tool, find the right issue, copy the stack trace, paste it somewhere the LLM can see it, then start.
The Sentry MCP server is a remote HTTP server hosted by Sentry, which means there’s no Docker container to maintain and no local process to babysit. You authenticate once with a personal access token and Claude Code can pull issue details, search across projects, fetch event payloads, and read breadcrumbs directly into context.
The install — three commands, two integrations
Here’s the actual setup. GitHub first:
claude mcp add github \
-e GITHUB_PERSONAL_ACCESS_TOKEN=ghp_your_token \
--scope user \
-- docker run -i --rm \
-e GITHUB_PERSONAL_ACCESS_TOKEN \
ghcr.io/github/github-mcp-server
Then Sentry. Sentry runs as a remote HTTP server, so the syntax is different:
claude mcp add --transport http sentry https://mcp.sentry.dev/mcp \
--scope user \
-H "Authorization: Bearer YOUR_SENTRY_PAT"
Verify with claude mcp list. You should see both servers reporting healthy. If Sentry returns a 401, the token doesn’t have the right project scopes — Sentry’s tokens are project-scoped, not org-scoped, so this trips up people who are used to GitHub PATs.
One configuration detail worth noting: I use --scope user for both. Project scope writes to .mcp.json in the repo, which is fine for team-wide tools but wrong for personal credentials. User scope keeps the token in your own config and out of the repo.
The prompt pattern that makes it work
The naive approach is “fix Sentry issue 12345.” That works but burns tokens because Claude has to discover the tool, fetch the issue, parse the stack trace, identify the file, and only then start reasoning about the fix. With Tool Search — the on-demand tool discovery that ships with Claude Code — the cost is lower than it used to be, but it’s still slower than necessary.
The pattern I’ve settled on is more directive: “Pull Sentry issue PROJECT-12345, identify the file and line from the stack trace, read the surrounding context, and draft a fix as a branch off main. Don’t open the PR yet.” That gives Claude a strict sequence and lets me review the branch before anything goes to GitHub.
The “don’t open the PR yet” part matters. When you chain two write-capable MCP servers, the failure mode is that Claude races ahead and pushes a half-baked fix because it has the tools and the authority. Constraining the action surface in the prompt is how you keep this useful instead of dangerous.
What breaks, and how to know
Three things have failed for me in the last month and each one is worth knowing.
First: Sentry rate-limits aggressively. If you’re working through a long incident and Claude is making repeated calls, you’ll hit the limit and the tool calls will start returning errors mid-conversation. The fix is to ask Claude to dump everything it needs from Sentry in one call, then work from that context. The token cost is higher upfront but the workflow is more reliable.
Second: GitHub MCP via Docker has a cold-start cost on the first call of a session — typically two to four seconds while the container spins up. This is fine but it does mean the first response feels slow. If you’re on a Mac with Apple Silicon, the container image is multi-arch and works without the --platform linux/amd64 flag.
Third: when both servers are connected and you have other MCP servers installed, Claude will sometimes route a Sentry-shaped question through GitHub’s search instead. The fix is to name the tool in the prompt — “use the Sentry MCP to fetch issue X” — rather than trusting the routing. This is a known cost of running many servers and is the trade-off you accept for breadth.
The pricing reality
Sentry MCP is free to use if you have a Sentry account — there’s no additional charge for the MCP layer. The cost comes from the Claude API tokens you burn pulling Sentry data into context. A typical issue investigation runs 8,000 to 15,000 input tokens depending on stack trace length and breadcrumb count. On Sonnet 4.6 that’s roughly $0.02 to $0.05 per investigation, which is trivial compared to the engineering time saved.
GitHub MCP is the same story — free server, you pay only for tokens. The Docker image is open source under github/github-mcp-server on GHCR.
What I’d install next
After GitHub and Sentry, the next install that earns its keep is Postgres if you have a database, or Linear if your team uses it for issue tracking. The pattern is the same in every case: the MCP server you want is the one that eliminates the highest-frequency context switch in your day, not the one with the most features. Audit your own tab-switching for a week. Whichever app you alt-tab to most often is the next MCP server worth wiring in.
The deeper lesson is that MCP changes the shape of what a coding agent is for. Without integrations, Claude Code is a smart autocomplete. With two well-chosen MCP servers, it becomes the connective tissue between alert, code, and ship — which is most of what engineering work actually is.
Almost every developer I trust has both Claude Code and Cursor open at the same time. The “which is better” question is the wrong one. The real question is which tool earns which job, and that answer has shifted twice in the last six weeks. Cursor 3.0 landed on April 2 with the Agents Window, Anthropic shipped Agent View into Claude Code on May 11, and Cursor Composer 2.5 dropped on May 18 — yesterday. If you locked in your mental model of these tools at the start of the year, it is already stale.
Here is the honest version of where they stand right now, where each one loses, and how I am actually using them in May 2026.
The pricing is closer than the discourse suggests
Both Pro tiers start at $20/month. Cursor knocks that to roughly $16 on annual billing, Anthropic to $17 on annual. From there the price ladders are nearly mirror images: Cursor sells Pro+ at $60 and Ultra at $200; Claude Code sells Max 5× at $100 and Max 20× at $200. Cursor Business is $40/seat with admin controls and centralized billing. Claude Code routes team buyers through Team Premium, which lands somewhere between $100 and $150 per seat depending on configuration.
For a ten-person engineering team, that math gets real. Cursor Business at $40 × 10 is $400/month. Claude Code via Team Premium is roughly $1,000–$1,500/month for the same headcount. That is a 2.5×–3.75× spread, and it is the single biggest reason Cursor still wins net-new enterprise pilots in 2026. Sticker shock is a feature, not a bug, in procurement.
Token efficiency cuts the other way. In side-by-side benchmark runs, Claude Code on Opus 4.7 has been hitting roughly 5× lower token usage than Cursor’s agent on identical tasks — one widely circulated benchmark showed 33K tokens vs 188K tokens for the same refactor. If you are on metered API pricing rather than a flat plan, the headline seat price is misleading. The plan tier you actually need depends on whether your team mostly types alongside the agent (Cursor’s strength) or dispatches autonomous jobs and walks away (Claude Code’s strength).
The May 2026 feature gap, honestly
Claude Code spent the spring building out parallelism. The headline is Agent View, which shipped in Claude Code v2.1.130 on May 11. Running claude agents opens a single CLI dashboard showing every background session, which ones are waiting on input, and which are still grinding. You can dispatch a session, send it to the background, and pull it forward only when it has a question. Combined with subagents — which already let you scope tool access and route to claude-haiku-4-5-20251001 for cheap exploration work before handing off to claude-opus-4-7 for the actual edits — you now get both horizontal parallelism between sessions and vertical parallelism inside one. The /goal command, also from this release window, lets you define outcome-based tasks that run with minimal supervision. Rate limits doubled in the same release window.
Cursor’s answer is the Agents Window from Cursor 3.0 (April 2), expanded yesterday by Composer 2.5. The Agents Window is the same idea as Agent View but lives inside the IDE rather than the terminal — multiple background agents, each in its own sandboxed checkout, running tests and shell commands while you keep editing. Composer 2.5 is Cursor’s house frontier model, tuned for low-latency agentic loops; Anthropic claims most turns complete in under 30 seconds, with a smaller Composer 2 variant doing cheap coordination work and calling out to stronger third-party models only when needed.
The contours: Claude Code’s parallelism story is built around a CLI agent that lives in your repo and treats the editor as optional. Cursor’s parallelism story is built around an IDE that treats the agent as one of several panes. Neither approach is obviously correct. Which one feels right depends on whether you already live in your terminal or your editor.
MCP support is finally a tie
This was Claude Code’s structural advantage all the way through 2025 — native Model Context Protocol support, which let you wire the agent to Postgres, Notion, Linear, internal APIs, anything that spoke MCP. That moat is gone. Cursor shipped native MCP support during the 3.0 cycle and the rough edges are now mostly sanded down. Both tools can query your database schema mid-session, both can hit your Linear or Notion workspace, both let you write custom MCP servers for internal tooling.
The remaining difference is ecosystem inertia. The Anthropic-published MCP servers tend to land in Claude Code first, and the third-party MCP server registry skews toward Claude Code usage patterns. If you are wiring up esoteric internal systems, expect to write more glue code on the Cursor side. If you are connecting standard SaaS, both tools are fine.
Where Claude Code still wins outright
One-million-token context on Opus 4.7, generally available since March, with no surcharge — a 900K-token request costs the same per-token rate as a 9K one. For codebases above roughly 200K tokens of relevant context, this is decisive. Cursor in “auto” mode picks a model and manages context for you, which is fine for small repos and unreliable for large ones. When I am asking a question that genuinely requires the agent to hold most of a service in its head — cross-service refactors, undocumented legacy code, migration planning — I open Claude Code.
The other Claude Code win: the agent will happily run for an hour on a hard problem without checking in, then come back with a working branch. Cursor’s agent prefers shorter loops and more interaction. That is a design choice, not a defect on either side, but it makes Claude Code the right answer for “go fix this entire test suite while I am in standup.”
Where Cursor still wins outright
Anything where you want the agent to be a faster you, not a substitute for you. Inline completion is still better in Cursor. Tab completion is still better in Cursor. The “watch my edits and infer the pattern” loop is still tighter in Cursor. If 80% of your day is writing code with occasional AI assistance, the IDE wraps the model better than a CLI does, no matter how good the CLI gets.
The other Cursor win: cost discipline at scale. Composer 2 doing cheap coordination and calling out to Opus or GPT only when needed is a smart cost-management pattern, and it shows up in your monthly bill. Cursor’s @codebase, @docs, @web, and @file mentions let you constrain the context window manually, which means fewer tokens chewed up by speculative retrieval.
How I actually use them
Cursor for the 80% — daily edits, feature work, bug fixes where I am still doing most of the thinking. Claude Code for the 20% — anything where I want to dispatch the agent and stop watching. Migrations. Test suite repair. Schema refactors that touch fifteen files. Anything where the right loop is “kick it off, go to lunch, come back to a PR.”
The decision rule that keeps me sane: if I will be in the editor anyway, I use Cursor. If I would otherwise be doing something else while waiting, I use Claude Code’s Agent View and let it run.
The tools are converging on feature parity at the surface — both have agent dashboards, both speak MCP, both have background sessions, both ship frontier models. The differences left are about texture: where you live (terminal vs editor), how much autonomy you want to grant in a single turn, and whether your spend looks more like a flat subscription or a metered API line item. Pick the texture that matches how your day already runs. Switching cost is low. Switching pain is real.
There is a workflow gap most Claude Code users walk straight into and never quite close. CLAUDE.md tells Claude what should happen. Plan mode lets you see what Claude intends to do. Hooks decide what Claude is physically allowed to do. Pick any one of those in isolation and you get a tool that is impressive in a demo and unreliable in a real repo. Pair plan mode with hooks the right way and Claude Code stops being a chat surface and starts behaving like a constrained junior engineer you can leave alone for an hour.
This is the workflow I have moved every non-trivial repo onto. It is not the simplest setup — that would be raw claude with a CLAUDE.md and trust. It is the setup that survives the moment Claude decides, with great confidence, to delete the wrong file.
The three layers, and why most people only use two
Claude Code as a programmable platform has three durable surfaces for shaping its behavior in 2026:
CLAUDE.md — the markdown memory file Claude reads at the start of every session. Project conventions, glossary, “don’t touch this directory,” coding style.
Plan mode — the read-only review gate, activated with Shift+Tab twice or /plan. No edits, no shell, no git. Claude proposes an implementation plan against the live codebase and waits.
Hooks — deterministic shell scripts that fire on specific tool calls or session events. Pre-commit linting, blocking edits to generated files, refusing pushes to main.
The standard pattern I see in repos is CLAUDE.md plus vibes. Sometimes plan mode for the big tasks. Almost no one is running hooks until they have been burned once. That is the wrong order. Hooks are not advanced — they are the thing that lets plan mode actually mean something.
The reason is empirical and uncomfortable: CLAUDE.md instructions get followed roughly 70% of the time. That is acceptable for “prefer arrow functions” and catastrophic for “don’t push to main.” Plan mode raises the floor on the high-stakes decisions because you see the plan before any tool runs. Hooks raise the ceiling on the boring ones because they execute regardless of Claude’s intent.
What the pairing actually looks like
The mental model: plan mode is for novel work where you need to inspect the strategy. Hooks are for recurring boundaries you do not want to inspect ever again. If you find yourself reviewing the same kind of decision in plan mode twice, that decision belongs in a hook.
A concrete setup from one of my repos:
CLAUDE.md — short. Project glossary, the test command, the “production data is in prod/ and is read-only” rule, the rule that all new files in src/ need a test in tests/. Maybe forty lines. No essay.
Plan mode discipline — anything that touches more than three files, anything that changes a public interface, anything that touches the database schema, I open with /plan. I read the plan. I push back. Then I let it run. For one-file edits, bug fixes I have already scoped, or doc changes, I skip planning. The cost of planning a two-line fix is higher than the cost of undoing it.
Hooks doing the actual enforcement. This is where the work lives. The hooks I run on every active repo:
A PreToolUse hook on Bash that blocks any command matching git push.*main, rm -rf, or any reference to a path under prod/. Returns a non-zero exit and tells Claude what to do instead.
A PreToolUse hook on Edit and Write that refuses any file path matching the generated-code globs from .gitattributes. If the file is autogenerated, Claude is rewriting source-of-truth, not output.
A PostToolUse hook on Edit that runs the linter on just the touched file and surfaces the diagnostics back to Claude. Cheap, fast, closes the loop without waiting for the next test run.
A Stop hook that runs the test suite. Claude does not get to mark the task done if tests are red. This single hook eliminated about 80% of my “it said it was done but” moments.
That last one is the one I would put in every repo before anything else. Without it, Claude verifies its work using its own judgment, which degrades as context fills. With it, each red-to-green cycle is an unambiguous external signal that the work is actually done.
Where this pairing earns its keep
Two scenarios where the plan-mode-plus-hooks combination pays for the setup time:
The unfamiliar-codebase refactor. Claude in plan mode reads the codebase, proposes a refactor across eight files, lists what it will touch and what it will leave alone. You scan the plan, notice it wants to modify a file in a directory that should be read-only, and instead of arguing in chat you add a hook. The hook is now permanent. The next session cannot make the same mistake.
The long-running, multi-step job. You send Claude off to add a feature with twelve subtasks. You are not watching. The Stop hook running tests means Claude either finishes with a green suite or stops and reports. The push-to-main hook means even if Claude decides the merge looks fine, it physically cannot ship it. You get back, read the report, merge. The autonomy is real because the guardrails are real.
What this pattern is not
It is not a replacement for reading Claude’s diffs. Hooks catch categorical mistakes — wrong directory, wrong branch, wrong command — and miss subtle ones, like a refactor that compiles and passes tests but breaks a contract no test covered. Plan mode catches strategic mistakes — wrong approach, wrong scope — and misses tactical ones, like an off-by-one. You still review code. You just stop spending review time on things a script can check.
It is also not a substitute for subagents or skills. Hooks are deterministic enforcement. Subagents are context isolation for parallel work. Skills are reusable procedural knowledge. The Anthropic team’s own framing — start with skills, add hooks when you need deterministic enforcement, add subagents when parallel work or context isolation matters — is correct, and the three layers compose. But the order most practitioners actually need is the inverse of the order they reach for. Most teams reach for subagents first because they sound powerful. Hooks are what makes any of it trustworthy.
The setup that gets you to a usable baseline
If you have one hour, do this in this order:
First, write a forty-line CLAUDE.md. The test command, the build command, the directory rules, the glossary. Do not try to write an essay about your codebase. Claude will read it every session — keep it dense.
Second, add three hooks: a PreToolUseBash hook blocking destructive commands on your protected paths, a PostToolUseEdit hook running the linter on the touched file, and a Stop hook running the test suite. Twenty lines of shell each. None of them require any framework — they are just executables that read JSON from stdin and exit non-zero to block.
Third, develop the habit of /plan for anything you would not be comfortable letting a new contractor commit without review. For everything else, let it run.
That is the baseline. You can layer on subagents, MCP servers, skills, custom slash commands — all of it is useful, none of it is required to ship reliably. The reliability comes from the boring layer: a memory file Claude reads, a plan mode you actually use, and hooks that mean what they say.
The Claude Code documentation will teach you the syntax for any of this in an afternoon. The pattern is the part that took a year of watching it go wrong to settle on.
Sources: Anthropic’s Claude Code documentation, the model list at the Anthropic docs site (verified at runtime), and a year of repos.
Last week I wrote about the three-file split every team should set up in their repo: CLAUDE.md, .claude/settings.json, and .claude/settings.local.json. That gets a team to a sane shared baseline. It does not stop a single engineer with admin rights on their laptop from disabling every guardrail you wrote.
If you are deploying Claude Code to more than a handful of engineers — anyone past Series B, anyone regulated, anyone whose CISO has asked a single pointed question about AI tooling — repo-level settings are insufficient. The control you want is managed-settings.json, and most teams I talk to either do not know it exists or have not deployed it.
Where managed-settings.json Actually Lives
Claude Code reads settings in a strict precedence order. Managed settings sit at the top and cannot be overridden by anything a user does in their repo, their home directory, or their environment. The file location depends on the OS:
You push the file via whatever you already use to manage developer machines. On macOS that is MDM — Jamf, Kandji, Mosyle. On Windows it is Group Policy Preferences. On Linux fleets, your config management tool of choice — Ansible, Chef, whatever survived your last platform team rewrite. The file does not need to be created by Claude Code itself. It just needs to be present at the path above, owned and writable only by an admin account, and readable by the user running claude.
The One Rule That Earns Its Keep: permissions.deny
Of every field in managed-settings.json, the one that pays for the entire deployment effort is permissions.deny. Deny rules at the managed-settings tier take effect regardless of any allow or ask rules at lower scopes. A user cannot grant themselves permission to do something an admin has denied — not in their project settings, not in their personal settings, not via a one-time CLI flag.
Concretely, here is a minimum-viable managed file for a team that wants to stop the obvious foot-guns:
That blocks Claude from curl-ing arbitrary URLs (the most common vector for accidental data exfiltration in agentic loops), reading anything in an .env file, and deleting filesystem roots in a Bash one-liner gone wrong. It does not stop legitimate work. It stops the long tail of “I didn’t realize it would do that.”
The Drop-In Directory Is the Underrated Piece
The single-file model breaks the moment you have more than one team contributing policy. Security wants curl blocked, platform wants kubectl delete blocked, the data team wants reads against the /data/prod/ mount blocked. Funneling all three through a single admin-owned file becomes a coordination tax.
Claude Code supports a drop-in directory at managed-settings.d/ in the same parent directory as managed-settings.json. Files in that directory are merged alphabetically — same convention as systemd and sudoers.d. Layout looks like this:
/Library/Application Support/ClaudeCode/
├── managed-settings.json # base policy
└── managed-settings.d/
├── 10-security.json # security team owns
├── 20-platform.json # platform team owns
└── 30-data.json # data team owns
Each team owns one file. They push their fragment through their own MDM channel without touching the others. Merge order is alphabetical, so the number prefix matters — later files override earlier ones for any overlapping keys, but permissions.deny rules always accumulate. Nothing a later file does can unblock something an earlier file denied.
What Belongs in Managed Settings — and What Does Not
Managed settings is a heavy hammer. Use it for things that must not be overridable. Everything else belongs in the repo’s .claude/settings.json, where engineers can iterate without filing a ticket.
Belongs in managed:
Deny rules for credentials, network egress, destructive shell operations
Telemetry / opt-out flags if your contract with Anthropic requires training data opt-out
Default model if you have a real reason to pin — most teams should let repos choose
Audit log paths if you are forwarding to a SIEM
Does not belong in managed:
Project-specific subagents or hooks (these live in the repo)
CLAUDE.md content (repo)
Allow rules — these are better as defaults at the repo scope, where engineers can adjust per-task
Verifying the Policy Is Actually Active
Pushing a config file is not the same as enforcing one. After deployment, run claude config list on a test machine and confirm the managed entries show up. Then attempt something the deny rule blocks — try a curl command, ask Claude to read an .env. The denial should be immediate and unambiguous, not a quiet skip. If a user can override it from their repo settings, the file is not at the right path or not readable by the user account running claude.
Model Selection at the Org Level
If you do pin a default model in managed settings — and I would argue most teams should not — read the model docs at docs.anthropic.com/en/docs/about-claude/models before writing the version string. Model identifiers change. As of this writing the workhorse is claude-sonnet-4-6, the flagship is claude-opus-4-7, and the fast option is claude-haiku-4-5-20251001. Hardcoding a model string in a managed file that nobody touches for six months is how you end up running last year’s model in production.
Where This Approach Loses
Managed settings cover the local Claude Code process. They do not cover the Anthropic Console, the Claude web app, or any MCP server an engineer connects to manually. If your threat model includes data leaving via the web app, managed settings on developer laptops are not the answer — the Enterprise plan’s org-level controls and SSO are. The two layers compose. Neither replaces the other.
Managed settings also do nothing about an engineer who runs Claude Code on a personal machine outside MDM scope. That is a device management problem, not a Claude Code problem, and the fix is the same as it has always been: do not let unmanaged machines touch production code.
The 30-Minute Rollout
Pick one platform — start with whichever fleet is largest, usually macOS
Write the minimum-viable managed-settings.json above
Push it to one test machine via MDM, verify with claude config list
Try three things the deny rules should block; confirm all three are blocked
Roll to the rest of the fleet
Set up the managed-settings.d/ directory so other teams can layer their own fragments without coordination
The whole exercise is half a day of work for a platform engineer who already knows your MDM. The alternative is hoping every engineer reads the same Notion page about which commands not to run. Hope is not a security control.
Most “Claude Code changed my life” posts are vibes. The interesting case studies are the ones with a number attached — a PR count, a token spend, a defect rate, a codebase size. After spending the week reading every concrete writeup I could find and cross-referencing them against Anthropic’s own internal usage report, three patterns hold up. Everything else is marketing.
Here is what the credible Claude Code case studies actually say, what they share in common, and where the wheels come off when teams try to repeat them.
Case 1: The 350k-line solo codebase
The most cited solo-developer case study right now is a maintainer of a 350,000+ line codebase spanning PHP, TypeScript/React, React Native, Terraform, and Python. Since August 2025, 80%+ of all code changes in that codebase have been written by Claude Code — generated, then corrected by Claude Code after review, with only minimal manual refactoring. The author has been working in commercial software for 10+ years, so this is not a beginner overstating things.
The two operational constraints they call out are the ones that matter:
Context selection is the job. A 200k token context window is less than 5% of a codebase this size. Include the files that show your patterns, exclude anything irrelevant, and accept that “too much context” degrades output as badly as “too little.”
Speed parity is the gate. If an LLM implementation isn’t at least as fast as doing it yourself, you’ve added a tool and lost time. They keep working documents to 50–100 lines and start every task with the bare minimum context.
This is the case study to send to anyone asking “does Claude Code work on legacy code.” The answer is yes, but only after you treat context curation as a first-class engineering activity.
Case 2: Anthropic’s own internal teams
Anthropic published a usage report covering ten internal teams. It is the highest-signal document in the ecosystem because every example is from a team that has unlimited access and zero incentive to oversell it. The patterns worth stealing:
Data Infrastructure lets Claude Code use OCR to read error screenshots, diagnose Kubernetes IP exhaustion, and emit fix commands. The team is not writing prompts about Kubernetes — they’re handing Claude a screenshot and a goal.
Growth Marketing built an agentic workflow that processes CSVs of hundreds of existing ads with performance metrics, identifies underperformers, and uses two specialized sub-agents to generate replacement variations under strict character limits. Sub-agents matter here — a single agent loses the constraint discipline.
Legal built a prototype “phone tree” to route team members to the right Anthropic lawyer. Non-engineering team, real internal tool, shipped.
Finance staff describe requirements in natural language; Claude Code generates the query and outputs Excel. No SQL skill required from the requester.
The Claude Code product team itself uses auto-accept mode for rapid prototyping but explicitly limits that pattern to the product’s edges, not core business logic. The RL Engineering team reports auto-accept succeeds on the first attempt about one-third of the time. That’s the honest number to hold onto when someone tells you their agent “just works.”
Case 3: The Sanity staff engineer’s six-week journey
The single most useful sentence in any Claude Code case study this year came from a staff engineer’s six-week writeup at Sanity: “First attempt will be 95% garbage.” That’s not a complaint — it’s an operating manual. The engineer’s workflow runs three or four parallel agents, treats every first pass as a draft to be re-prompted, and reserves human attention for architecture and steering rather than typing.
This is also the case study that matches the Pragmatic Engineer’s February 2026 survey of 15,000 developers, which ranked Claude Code as the most-used AI coding tool on the market. The teams who report the biggest gains are not the ones treating it like autocomplete. They’re the ones running multiple threads, accepting that most first drafts are throwaway, and putting their senior judgment on review rather than authorship.
What every credible case study has in common
Cross-reference the three above with the dozen other writeups that include real numbers and the same five operational habits show up every time:
A written context doc. Every successful team has something Claude reads first — a CLAUDE.md, a .clauderules file, a project README that defines patterns and conventions. Teams without one get inconsistent output.
Sub-agents for constraints. One agent that has to remember the character limit, the style guide, the schema, and the deadline will drop one of them. Two agents — generator and constraint-checker — won’t.
Real review on the way in. The 80% figure from the 350k-LOC case includes “corrected by Claude Code after review.” Nobody is shipping unreviewed agent output to production and reporting wins.
A measurement loop. Faros and Jellyfish reports both show teams using Claude Code analytics to track PRs and lines shipped with AI assist. The teams that measure ship more; the teams that don’t, drift.
Honest scoping. Auto-accept on edges, synchronous prompting on core business logic. Every team that ignores this distinction generates the “tech debt nightmare” posts.
Where the case studies break down
Two warnings from the data. First, Jellyfish’s AI Engineering Trends report shows a 4.5x increase in companies running agentic coding workflows, but most engineering teams using these tools spend $200–$600 per engineer per month and report a 1.6x productivity multiplier — not the 10x that vendor marketing implies. The case studies you read are the wins; the median outcome is more modest.
Second, the model version you run matters more than any workflow trick. As of this week the flagship is claude-opus-4-7, the workhorse is claude-sonnet-4-6, and the fast option is claude-haiku-4-5-20251001. Opus 4.7 lifted resolution on a 93-task coding benchmark by 13% over Opus 4.6 — including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve. Teams running on stale model strings are leaving real capability on the table.
The takeaway
If you only steal one thing from the credible case studies, steal the context discipline. The 350k-LOC maintainer keeps documents to 50–100 lines. Anthropic’s own teams use sub-agents to enforce constraints. The Sanity engineer runs parallel agents and treats first drafts as garbage by default. None of these patterns require a special prompt or a hidden flag. They require deciding, before you start a task, what Claude is allowed to see and what it isn’t.
That’s the whole game. The teams shipping 80% of their code with Claude Code aren’t using a better model — they’re feeding it a better context.
Installing Claude Code is the easy part. Deploying it across a team in production is the part most guides skip.
Most of the published guidance on installing Claude Code stops at “run npm install -g and you’re done.” That’s enough for a developer playing on a laptop. It is not enough for a team that wants to run Claude Code in production — in CI, in shared infrastructure, behind a firewall, with cost controls, and with the new Agent SDK billing model that takes effect June 15, 2026.
This article is the production deployment guide. Triple-sourced against Anthropic’s own Claude Code documentation, the github.com/anthropics/claude-code-action repo, and Anthropic’s announced June 15 billing model. Verified May 15, 2026.
The three install paths and which to pick
Per Anthropic’s official Claude Code docs, there are three supported ways to install Claude Code. They produce the same underlying binary but make sense in different operational contexts.
1. Standalone installer. A native installer for macOS, Windows, and Linux that drops the Claude Code binary in a system path. This is the cleanest install for individual developers — no Node.js required, no npm dependency, predictable upgrade behavior. Use this on workstations where the operator owns the machine.
2. npm global package.npm install -g @anthropic-ai/claude-code. Requires Node.js 18 or later. Pulls the same native binary as the standalone installer through a per-platform optional dependency, then a postinstall step links it into place. Use this when you already manage developer tools through npm and want one less install path to track. Supported platforms: darwin-arm64, darwin-x64, linux-x64, linux-arm64, linux-x64-musl, linux-arm64-musl, win32-x64, win32-arm64.
3. Desktop app. A desktop-class application distributed via .dmg on macOS and MSIX/.exe on Windows. This is the path most teams will deploy to non-developer staff, and it integrates with enterprise device management tools like Jamf, Kandji, and standard Windows MSIX deployment.
If you are deploying across a team larger than a handful of developers, mix-and-match: standalone or npm for engineering workstations, desktop for everyone else.
The npm install gotchas worth knowing before you ship
Two things in Anthropic’s official docs are worth flagging because they will save you from a whole class of bug reports later:
Don’t use sudo. Anthropic’s setup documentation explicitly warns against sudo npm install -g @anthropic-ai/claude-code. It can lead to permission issues and security risks. If you need a global install on a machine where your user can’t write to the npm prefix, fix the npm prefix first (point it at a user-writable directory) rather than escalating with sudo.
Don’t use npm update for upgrades. The right command per Anthropic’s docs is npm install -g @anthropic-ai/claude-code@latest. npm update -g respects the original semver range and may not move you to the newest release. This trips up CI pipelines that try to keep Claude Code current via update; they will sit on a stale version forever.
Production deployment considerations
The single most important piece of context for a production Claude Code deployment in 2026: the billing model changes on June 15, 2026.
Before June 15, Claude Code interactive sessions and claude -p non-interactive runs both draw from your normal subscription usage limits. Starting June 15, interactive Claude Code keeps using subscription limits as before, but claude -p and direct Agent SDK usage move to a separate per-user monthly Agent SDK credit pool ($20 Pro, $100 Max 5x, $200 Max 20x, $20-$100 Team, up to $200 Enterprise).
For teams running Claude Code in CI, in cron jobs, in shell scripts, in GitHub Actions workflows — anywhere the trigger is automated rather than a human — this changes the economics. Plan capacity against the new credit pool, not the legacy shared subscription pool. Full breakdown in our Agent SDK Dual-Bucket Billing article.
Three other production considerations:
Network configuration. Behind a corporate firewall, you’ll need to allowlist Anthropic’s API endpoints, configure proxy settings, and potentially route through an LLM gateway. Anthropic’s network configuration documentation covers the specifics.
Enterprise device deployment. Per Anthropic’s official docs, the desktop app distributes through standard enterprise tools — Jamf and Kandji on macOS via the .dmg installer, MSIX or .exe on Windows. If your IT team already has a deployment workflow for similar developer tools, Claude Code drops into it without anything special.
API key management. If your team uses Claude Developer Platform API keys instead of (or alongside) subscription auth, manage them like any other production secret — vault them, rotate them, scope them per environment, never check them into source control. This becomes more important after June 15 because API key usage is the recommended path for sustained shared automation, and unintended sprawl gets expensive.
Claude Code GitHub Actions: the team multiplier
The fastest way to get team-level value from Claude Code is the official GitHub Actions integration. From Anthropic’s documentation and the public github.com/anthropics/claude-code-action repository:
The setup command. The cleanest install is to run /install-github-app from inside Claude Code in your terminal. It walks you through installing the GitHub App, configuring the required secrets, and wiring the workflow file. Manual setup also works — copy the workflow YAML from Anthropic’s docs and add the ANTHROPIC_API_KEY secret to your repository settings — but the install command saves the assembly time.
The interaction model. Once installed, mentioning @claude in a pull request comment or an issue triggers Claude Code to act on the context. Claude can analyze the diff, create new PRs, implement features described in an issue, fix reported bugs, and respond to follow-up comments — all while adhering to whatever conventions you’ve documented in your repository’s CLAUDE.md file.
Three use cases worth separating clearly.
Automated code review. Claude Code reads the diff on every pull request and posts inline comments flagging potential issues, suggesting improvements, or checking for convention violations. Highest signal-to-noise when path-filtered to relevant code only.
Issue-to-PR automation. Tag @claude on a well-described issue and Claude Code opens a PR implementing it. Best for small, well-scoped changes; less useful for architectural work.
On-demand assistance. Reviewers tag @claude mid-PR to ask questions, request explanations, or get a second opinion before merging. The most defensible use case because it keeps a human in the decision loop.
Pick the use case that matches your team’s actual bottleneck. Running all three at once on every PR is the fastest way to burn through your usage budget without proportionate value.
Cost expectations at team scale
Independent reports as of May 2026 put Claude Code GitHub Actions PR-review costs at roughly $15-25 per month for a team of 3-5 developers doing 10-15 PRs per week, billed against a Claude Developer Platform API key at Sonnet rates. That figure should be treated as directional — your actual cost depends on PR size, how many tools you’ve configured, model selection, and how aggressive your path-filtering is.
Two cost controls that materially change the math:
Path filters. Trigger Claude Code only on file changes that actually need review. Skipping documentation, generated files, and lockfile-only PRs cuts the bill substantially.
Concurrency limits. GitHub Actions concurrency settings prevent Claude Code from running multiple instances against the same branch at once. Without this, force-pushes and rapid-fire updates can stack runs.
If you are running Claude Code on every PR across an active team, you will hit Anthropic API rate limits. The mitigation is path filters, concurrency limits, and batching — none of which are speculative; they are documented patterns.
The CLAUDE.md file is not optional
Whatever your install path and whatever your use case, the single piece of project context that has the largest effect on Claude Code’s output is the CLAUDE.md file at the root of your repository. This is where you tell Claude Code what your project is, what conventions to follow, what tools are available, what to avoid, and what success looks like.
If you skip it, Claude Code is reasoning from the files alone — useful but generic. If you write it, Claude Code is reasoning with your team’s context and your specific codebase rules. The difference shows up in the first ten minutes of use.
A practical CLAUDE.md for a production team usually includes: the project’s purpose and stack, naming conventions and folder structure, testing requirements, lint and format rules, deployment considerations, what kinds of changes need human review, and explicit prohibitions (“never commit migrations directly to main”, “always update X when you change Y”). Keep it concise — verbose CLAUDE.md files inflate every per-turn token cost across the team.
What to actually do this week
Pick your install path per role (standalone or npm for developers, desktop for everyone else).
Install Claude Code on one workstation and run through the quickstart end-to-end before rolling to the team.
Write a real CLAUDE.md for your primary repository before anyone uses Claude Code on it. Even a 100-line version is far better than nothing.
If you want team-level value, install the GitHub Actions integration — but pick one use case (code review, issue-to-PR, or on-demand help), not all three at once.
Set path filters and concurrency limits in your workflow before you put Claude Code on every PR.
Frequently Asked Questions
What’s the difference between the npm install and the standalone installer?
None functionally — both install the same native binary. The npm path is convenient if you already manage developer tools through npm. The standalone installer is cleaner if you don’t want a Node.js dependency. Both upgrade through their own mechanism.
Why does Anthropic say not to use sudo with npm install?
Per Anthropic’s official setup documentation, sudo with global npm installs can create permission issues and security risks. The recommended fix is to configure your npm prefix to a user-writable directory, then install without elevated privileges.
How do I upgrade Claude Code installed via npm?
Run npm install -g @anthropic-ai/claude-code@latest. Don’t use npm update -g — it respects the original semver range and may not move you to the latest release. This is documented in Anthropic’s setup guide.
Does Claude Code work in CI/CD pipelines?
Yes. The official GitHub Actions integration is the recommended path for GitHub-based workflows. For other CI systems (GitLab, CircleCI, Jenkins), the underlying tool is the Claude Agent SDK plus claude -p. Both move to the new Agent SDK monthly credit pool on June 15, 2026.
How much does Claude Code GitHub Actions cost for a team?
Independent reports as of May 2026 estimate $15-25/month for a 3-5 developer team running PR review on 10-15 PRs/week at Sonnet rates with a Claude Developer Platform API key. Actual cost varies with PR size, tool configuration, model selection, and path filtering aggressiveness.
What’s the single biggest mistake teams make installing Claude Code?
Skipping the CLAUDE.md file. Without it, Claude Code reasons generically against your codebase. With even a basic CLAUDE.md describing your conventions and constraints, output quality improves substantially across every interaction. It is the highest-leverage 30-minute setup task.
Anthropic Claude Code documentation: Set up Claude Code and Advanced setup at code.claude.com (primary source for install paths, npm gotchas, enterprise deployment patterns)
Anthropic Claude Code GitHub Actions documentation at code.claude.com/docs/en/github-actions (primary source for the GitHub Actions integration setup and use cases)
github.com/anthropics/claude-code-action public repository (primary source for the action’s interaction model)
Anthropic Help Center: Use the Claude Agent SDK with your Claude plan (primary source for the June 15, 2026 billing change)
Independent cost analyses (KissAPI, OpenHelm, Steve Kinney) for the team-scale cost estimates — Tier 2 confirming sources
Cost figures and version specifics in this article are accurate as of May 15, 2026. Anthropic ships Claude Code updates frequently; the install paths and CLI commands are stable, but pricing and rate limits are the most likely figures to need re-verification.
If you’ve ever connected a few Model Context Protocol (MCP) servers to Claude Code and watched your usage limit drain faster than the work you actually did would explain, you’re not imagining it. There’s a real, documented, and sometimes substantial token cost to wiring MCP servers into your Claude environment — and most setup guides don’t mention it.
The short version: each MCP server you connect injects its complete tool schema into the context of every message you send. Multiple servers stack. The total overhead can range from a few thousand tokens for a single server up to roughly 18,000 tokens per turn when you’re running a typical multi-server developer setup. Anthropic’s own engineering team has acknowledged this in a public GitHub issue and shipped optimizations to reduce it.
This article walks through where the overhead actually comes from, how to measure your own setup, what Anthropic has changed in 2026 to ease the cost, and the concrete steps you can take to keep MCP useful without burning through your token budget.
What MCP actually is, briefly
The Model Context Protocol is an open standard created by Anthropic that lets Claude (and other LLMs that adopt the standard) connect to external tools and data sources through a common interface. Instead of writing a custom integration for every API or database you want Claude to access, you point Claude at an MCP server, and the server exposes its capabilities — file access, Slack messages, GitHub repos, database queries — in a format Claude can use.
It’s a real productivity unlock. It’s also why the token math gets complicated.
Where the token cost comes from
When you connect an MCP server to Claude Code (or any MCP-aware client), three things happen on every message:
1. Tool schema injection. Every tool the server exposes — every name, every description, every parameter definition — is included in the context Claude sees. A Slack MCP server with 10–15 tools typically adds about 2,000 tokens. A GitHub server is heavier. A custom internal-tooling server with verbose descriptions can run 5,000–8,000 tokens on its own.
2. Tool-use system prompt overhead. Anthropic’s documentation confirms that whenever tools are present in a request, a special system prompt is automatically prepended that teaches the model how to use tools. For Claude 4.x models with tool_choice: auto, that’s an additional 346 tokens per request. The bash tool adds 245. The text editor tool adds 700. The computer-use tool adds 735 plus a 466–499 token system prompt extension.
3. Stateless re-sending. Each message in a conversation is a fresh API request that includes the full conversation history plus the full tool schema. Claude does not “remember” your tools from the last turn the way a human remembers a colleague’s job description. Every turn pays the schema cost again.
That’s the math. Now multiply by the number of MCP servers you have connected. A developer running Slack + GitHub + a database connector + an internal custom server can easily land in the 15,000–20,000 tokens-per-turn range — and that’s before you’ve typed your actual question.
The 18,000-token figure, sourced
The “up to 18,000 tokens per turn” number comes from a combination of public sources verified May 15, 2026:
Anthropic’s own GitHub repo for Claude Code, issue #3406, titled “Built-in tools + MCP descriptions load on first message causing 10–20k token overhead.” Anthropic engineers acknowledged the issue and have shipped progressive optimizations against it.
Independent analysis by MindStudio measuring real Claude Code sessions with multiple MCP servers attached.
Anthropic’s official Claude Code documentation on cost management explicitly recommends running /mcp to inspect connected servers and disabling unused ones to control token consumption.
The exact number for your setup will be different. The shape of the problem is the same.
Why this matters more than it looks
Claude’s standard context window is 200,000 tokens. Losing 18,000 of those to tool definitions before you start typing represents about 9% of your effective working space. That’s a real ceiling cost — but it’s not the part that hurts most.
The part that hurts is the cumulative bill. If you’re on a Claude subscription with a usage limit, every turn through Claude Code is paying the full schema cost again. A workflow that takes 30 turns of back-and-forth burns 540,000 tokens worth of tool definitions across that session — even if the tool descriptions never change. On the API at standard Sonnet 4.6 rates, that’s about $1.62 in pure schema overhead per session, before any of the actual work gets billed.
Multiply by a team of engineers running Claude Code daily, and the overhead becomes the largest single line item in your token spend.
What Anthropic has changed in 2026
Anthropic has shipped two meaningful optimizations against MCP token bloat over the past few months:
Deferred tool loading. In recent Claude Code releases, MCP tool definitions are no longer all loaded into context at the start of a session by default. Tool names enter context, but the full schemas only load when Claude actually invokes a particular tool. This is a substantial improvement for sessions where you have many tools available but only use a few.
Tool Search. A new built-in search mechanism lets Claude discover relevant MCP tools on demand rather than carrying them all in context. One independent measurement reported a Claude Code MCP context cut of 46.9% — from roughly 51,000 tokens down to 8,500 tokens — by using Tool Search instead of full upfront loading.
These optimizations help, but they don’t make the overhead zero. The baseline cost of having any MCP server connected at all is real, and you still pay it on every turn even with deferral active.
How to measure your own MCP token cost
Two practical methods work for most setups:
Method 1 — The /mcp command. In Claude Code, run /mcp to see every server currently connected. For each one, check how many tools it exposes. Anthropic’s documentation explicitly recommends this as the first step to controlling MCP costs.
Method 2 — Token-count delta. Send a single message in Claude Code with no MCP servers connected and note the input token count from the API response. Reconnect your MCP servers one at a time. The delta in input tokens between configurations is the per-turn cost of each server. This is the most precise way to know your own number.
Anything north of about 8,000 tokens per turn in pure MCP overhead is worth optimizing. North of 15,000 is a flag.
Concrete steps to control MCP token cost
Disable MCP servers you aren’t actively using. The single highest-leverage move. If you connected a server two weeks ago for one experiment and never went back to it, every turn you’ve taken since has been paying for it.
Prefer CLI tools over MCP servers when both exist. Anthropic’s own cost-management guidance notes that tools like gh, aws, gcloud, and sentry-cli remain more context-efficient than equivalent MCP servers because they don’t add per-tool listing overhead. Claude can simply invoke them via the bash tool.
Use MCP gateways for large server counts. If you genuinely need many tools available, gateway products (Maxim, Milvus-backed setups, others) consolidate tools and surface only relevant ones per query, cutting net overhead substantially.
Run a complex CLAUDE.md audit. Long project-level CLAUDE.md files compound the per-turn baseline. Treat CLAUDE.md as an asset that’s expensive to keep verbose.
Watch for context compounding. In long Claude Code sessions, conversation history grows alongside the tool schema cost. If you’re running a workflow longer than 20 turns, periodically clear context (/clear) to reset the per-turn cost to baseline.
Frequently Asked Questions
Does every MCP server cost 18,000 tokens?
No. The 18,000-token figure is for a typical multi-server setup with several connected servers and built-in tools active. A single small MCP server (5–10 tools, concise descriptions) might only add 1,500–3,000 tokens. The cost scales with the number of servers and the verbosity of their tool definitions.
Why does Claude reload the tool definitions every turn?
The Claude API is stateless. Every message is a fresh API request containing the full conversation history and the full tool schema. The model has no memory between requests, so the schema must be present every time tools could be used. Recent deferred-loading optimizations reduce this for unused tools, but anything Claude actually needs still loads each turn.
How do I see what’s loaded in my Claude Code environment?
Run /mcp in Claude Code to list every connected MCP server and its tool count. To check the actual token cost, send a test message and inspect the input token count returned by the API.
Are CLI tools really cheaper than MCP servers?
Yes, for tools that have both options. CLI tools accessed via the bash tool only add the bash tool’s 245-token overhead. An equivalent MCP server adds its full tool schema for every tool it exposes. For tools you use frequently, MCP can still be worth it for the structured interface; for tools you use rarely, CLI is more efficient.
Does this affect Claude on the web (claude.ai) too?
Web Claude does not use the same MCP server-connection model as Claude Code. The MCP token-overhead pattern primarily affects Claude Code, custom Agent SDK applications, and other developer-facing clients where you wire in MCP servers directly.
Will this get better in future Claude releases?
Likely. Anthropic has already shipped deferred tool loading and Tool Search in 2026, both of which materially reduce the per-turn overhead for unused tools. The architectural baseline (tools must be present in context to be invoked) is unlikely to change, but the practical cost should keep dropping as the deferred-loading optimizations mature.
Anthropic GitHub: anthropics/claude-code issue #3406, “Built-in tools + MCP descriptions load on first message causing 10-20k token overhead” (primary source for the overhead figure and Anthropic acknowledgment)
Anthropic Claude Code documentation: Connect Claude Code to tools via MCP and Manage costs effectively (primary source for /mcp command and CLI vs. MCP guidance)
Anthropic Pricing Documentation: tool-use system prompt token counts, bash/text-editor/computer-use overheads (primary source for the per-tool fixed costs)
Independent analysis: MindStudio (multiple Claude Code MCP measurements), Joe Njenga’s Tool Search 51K→8.5K measurement, Maxim and Scott Spence on optimization patterns (Tier 2 confirming sources)
Token-cost numbers in this article are accurate as of May 15, 2026. Anthropic is shipping MCP optimizations regularly, so the practical overhead may be lower in your environment than what’s described here.