Last refreshed: May 15, 2026
Microsoft is stitching together an everything app from acquisitions. Google is trying to unify a native stack it keeps fragmenting. Notion is doing something different — and arguably more interesting. It’s building the everything app from the database up, and it just made its most important move yet.
Definition: The Database-First Everything App
An AI-powered workspace where every piece of information — tasks, projects, docs, contacts, data — lives in a structured, queryable database, and agents can read, write, reason over, and act on that data autonomously. The database isn’t the backend. It’s the interface.
Yesterday Changed Everything for Notion
On May 13, 2026 — yesterday — Notion shipped version 3.5 and announced their full Developer Platform in a livestreamed product event. The tech press covered it as an AI agent story. They weren’t wrong, but they missed the bigger frame.
Notion didn’t just add agents. They introduced a new primitive called Workers — a hosted runtime for custom code that lets teams extend Notion without running their own servers. Database sync, agent tools, and webhook triggers all run through Workers. They launched the External Agents API, allowing any agent — ones you built, or ones from Claude, Codex, Decagon, and other partners — to work natively inside your Notion workspace. And they opened a developer platform that lets teams connect AI agents, external data sources, and custom code directly into their workspace.
Taken individually, these are nice product updates. Taken together, they’re an orchestration play. Notion is positioning itself not as a note-taker with AI features bolted on, but as the hub where people, agents, and data collaborate across every tool a team uses.
The Database Advantage Nobody Else Has
Here’s the thing that separates Notion from every other everything-app candidate — including Microsoft and Google.
Both Microsoft 365 and Google Workspace are document-first platforms. Their fundamental unit of work is a file: a Word document, a Google Doc, a PowerPoint, a Sheet. Files are great for humans to read. They’re terrible for AI to reason over at scale. You can’t ask an AI agent to “find every project where the status is blocked and the deadline is this week” across a folder of Word documents and get a reliable answer.
Notion’s fundamental unit is a database. Every page can be a database row. Every property is structured, queryable, filterable data. When Notion AI looks at your workspace, it doesn’t see a pile of documents — it sees a relational knowledge graph. Tasks have statuses. Projects have owners and deadlines. Contacts have properties. Everything is connected, typed, and queryable.
That’s not a feature difference. That’s an architectural difference. And it’s why Notion’s agents can do things that Copilot and Gemini agents fundamentally struggle with: operate reliably on your actual organizational data, not summaries of your documents.
The Agent Timeline: Faster Than Anyone Expected
Notion’s agent rollout has moved at a pace that’s easy to underestimate if you haven’t been watching closely. Here’s the actual timeline:
- September 18, 2025 — Notion 3.0: Agents. First AI agents launch. Autonomous data analysis and task automation. The starting gun.
- January 20, 2026 — Notion 3.2. Mobile AI, new model support, people directory. Agents go everywhere, not just desktop.
- February 24, 2026 — Notion 3.3: Custom Agents. Users can build their own agents from scratch. Over 21,000 custom agents built in the first free trial period alone. Notion reported 2,800 agents running 24/7 internally at Notion itself.
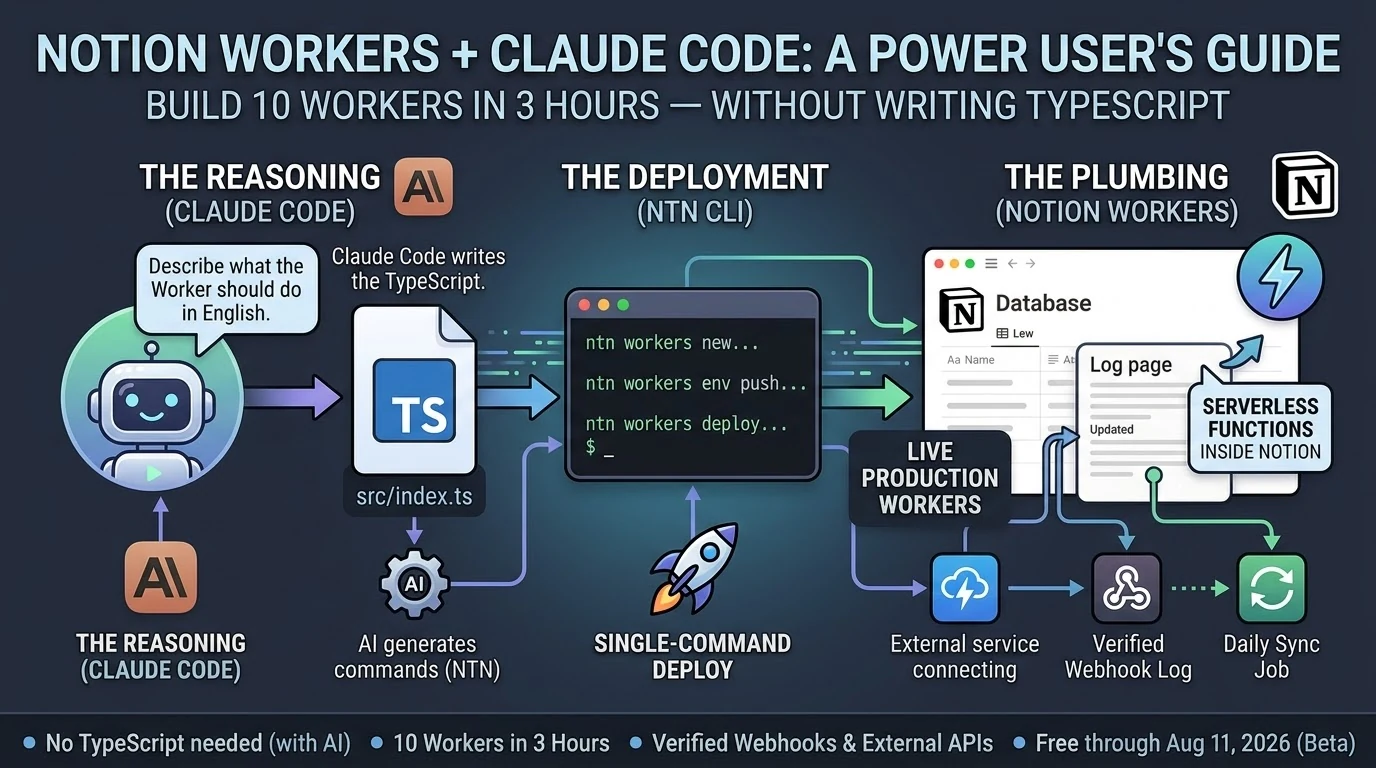
- March 2026. Workers introduced in alpha — a TypeScript-based framework for agents to talk to any service with an API. The coding layer for power users.
- April 14, 2026 — Notion 3.4. Calendar and inbox connectors. Notion AI can now schedule meetings and draft emails from inside your workspace.
- May 5, 2026. Custom Agent admin controls for enterprise — workspace-level credit limits, governance tools, compliance features.
- May 13, 2026 — Notion 3.5: Developer Platform. External Agents API, Workers out of alpha, database sync with no servers, full developer ecosystem launched.
That’s eight months from first agent launch to full developer platform. For context, Microsoft spent years building Azure OpenAI integration before Copilot reached feature parity with what Notion shipped in less than a year.
What the Notion Everything App Actually Looks Like Today
This isn’t theoretical. Here’s what a team running on Notion can configure right now:
- Your project data, always current. Databases synced from Slack, Google Drive, GitHub, Jira, Microsoft Teams, Salesforce, and Box — all flowing into Notion databases in real time, powered by Workers. No manual updates. No stale spreadsheets.
- Agents watching your work. Custom agents triggered by database changes, schedules, or webhooks — compiling status updates, flagging blocked tasks, escalating overdue items, answering team FAQs.
- Your inbox and calendar inside your workspace. Connect Gmail or Outlook and your calendar; Notion AI can schedule meetings and draft emails without leaving the tool your work already lives in.
- External agents working in your context. Claude, Codex, Decagon — agents you’ve built yourself via the External Agents API — all operating against your Notion databases with full context. Not generic AI. AI that knows your specific data.
- Plan Mode for complex operations. Before an agent makes large changes to your databases or pages, it stops, asks clarifying questions, and builds a plan for your approval. This is the governance layer that makes AI trustworthy in a business context.
- Your institutional knowledge, always accessible. Every decision, every project history, every team document — structured and queryable by agents that can synthesize across your entire knowledge base on demand.
The Model Behind It: Claude Opus 4.7
Unlike Microsoft (Copilot runs on GPT-4o and Azure OpenAI) and Google (Gemini family), Notion is built on Anthropic’s Claude. As of the January 2026 update, Notion runs Claude Opus 4.7 — Anthropic’s most capable model at the time of release — for its AI features and agent reasoning.
This is a strategic choice worth examining. Claude is specifically designed with a focus on reliability, honesty, and safe behavior in agentic contexts — qualities that matter enormously when an AI agent has write access to your company’s databases. Anthropic’s Constitutional AI training approach was built for exactly the kind of autonomous, long-running agent work that Notion is deploying.
The Notion + Claude combination isn’t just a vendor relationship. It’s an architectural alignment: a database-first workspace built on a model specifically designed for trustworthy agentic behavior. That’s a more coherent stack than either Microsoft or Google has assembled, where the AI model and the productivity platform were developed independently and integrated later.
Why “Database First” Beats “Document First” for the Everything App
Let’s make this concrete with a comparison most teams will recognize.
Ask Microsoft Copilot: “Which of our client projects are behind schedule this quarter?” Copilot will search your emails, scan your SharePoint documents, and produce a reasonable summary — but it’s reading prose, inferring structure, and hoping the documents are up to date. The answer is a best-effort synthesis, not a query result.
Ask a Notion agent the same question: it runs a database filter. Status = Behind. Quarter = Q2 2026. It returns an exact list in under a second, with links to every project, the responsible person, and the last update — because that data is structured. The agent didn’t infer anything. It read typed data.
That’s the difference between AI that helps you find things and AI that actually knows things. Notion’s database architecture is what makes the second kind possible at scale, without hallucination, without retrieval errors, without the AI making up a project that doesn’t exist.
The Honest Weakness: The 30-Second Wall
Here’s what you only learn by actually building inside the alpha — and we did.
Notion Workers runs in a 30-second sandbox with 128MB of memory. Each Worker is created through the Notion control panel, taking 3–5 minutes to spin up. The network is limited to an approved domain allowlist. Storage is ephemeral — nothing persists between runs. These aren’t theoretical constraints. They’re the real walls you hit when you try to move serious automation workloads into Notion.
We were in the Workers alpha. We built Workers. We set up custom agents. And we stress-tested the sandbox deliberately — forcing failures to find the exact break points, then running production workloads at 60% of the known ceiling as a stability rule. That’s the only honest way to operate inside a system this constrained: know where it breaks before you depend on it.
What we found changed our architecture. Heavy automations — multi-site WordPress SEO optimization passes across 18 sites, content pipelines, image generation, WP-CLI batch operations — couldn’t live inside Notion Workers. They’re multi-minute jobs, not 30-second jobs. Moving them to Notion would have meant engineering workarounds that added complexity without adding reliability.
So instead of moving Cowork automations into Notion as we originally planned, we moved them to Google Cloud Run. The notion-deep-extractor (crawls the workspace, extracts structured knowledge, logs to the Second Brain database — runs 3x daily) and the notion-maintenance bundle (archive sweeper, stale work detector, content guardian — runs daily at 6am UTC) all live on Cloud Run now, with Cowork scheduled tasks paused. The 18-site WordPress optimizer running Tuesday? Cloud Run. Not Notion.
This isn’t a knock on Notion. It’s an architectural reality that every builder needs to understand before they commit workloads. The right pattern — the one we’re now using and that Notion’s own documentation points toward — is Notion Workers as the trigger layer, Cloud Run as the execution layer. A Worker fires a signed POST to a Cloud Run endpoint, returns immediately (well under 30 seconds), Cloud Run runs the heavy job, then writes results back to a Notion database via the Public API. You get Notion as the orchestration and visibility layer without hitting the sandbox wall.
That hybrid is genuinely powerful. But it requires infrastructure that most small teams don’t have. If you don’t have a Cloud Run setup, a service account, and the deployment knowledge to wire this together, the 30-second limit will stop you cold on anything more complex than a lightweight API call or a database update.
Notion doesn’t own email. It connects to Gmail and Outlook. It doesn’t own a calendar — it integrates with yours. It doesn’t have a mobile OS or browser. Those gaps matter less than the sandbox constraint does for real production workloads. The everything app story is real — but the execution layer has hard limits that require a hybrid architecture to work around, at least until Workers matures beyond its current beta constraints.
Who Should Be Paying Attention Right Now
If you’re an agency, a service business, a content operation, or any knowledge-work team that already uses Notion — or has been considering it — the May 13 Developer Platform announcement changes your calculus significantly.
Custom Agents are available as an add-on for Business and Enterprise plans. Workers are free during the current beta period (billing starts August 11, 2026). The External Agents API is open now. This is the window to build before your competitors do.
The teams that spend the next 90 days wiring up their Notion databases, building their first custom agents, and connecting their external data sources will have a compounding advantage that’s very hard to replicate in 2027. The institutional knowledge that feeds these agents — the project histories, the SOPs, the client databases — takes time to build. Starting now is the only strategy that works.
The Bigger Picture: A Series on Who Wins the Everything App
This is the third article in an emerging pattern I’ve been thinking through: who actually builds the everything app, and what does their path look like?
Microsoft is building it through acquisitions and Copilot, stitching together LinkedIn, Azure, and the M365 suite. Google already owns the native stack — Gmail, Drive, Search, Android — and is trying to unify it through Gemini Enterprise and Workspace Studio after years of product fragmentation. Notion is building it from the database up, betting that structured data plus open agents beats document-first platforms with AI bolted on.
None of them has won yet. All three bets are live. The winner won’t be the company with the most features — it’ll be the one that earns enough trust to become the single place where your work actually lives.
Notion’s database-first architecture is the most interesting bet of the three. It’s also the most fragile — dependent on integrations, constrained by not owning the OS or the inbox, limited by whatever Anthropic does with Claude pricing and capabilities. But if it works, it works in a way the others can’t easily copy. You can’t retrofit a database architecture onto a document platform. You have to start over.
Microsoft and Google aren’t starting over. Notion never had to.
Frequently Asked Questions
What are Notion Custom Agents?
Notion Custom Agents are AI teammates that handle repetitive tasks autonomously — answering FAQs, compiling status updates, automating workflows — triggered by schedules, database changes, or webhooks. They launched in February 2026 (Notion 3.3) and are available as an add-on for Business and Enterprise plans. Over 21,000 were built during the free trial period alone.
What is Notion Workers?
Notion Workers is a hosted cloud runtime for custom TypeScript code, introduced in alpha in March 2026 and fully launched with the Developer Platform on May 13, 2026. It powers database sync, agent tools, and webhook triggers — letting teams extend Notion to connect any service with an API, without running their own servers. Workers are free during the beta period through August 10, 2026.
What AI model does Notion use?
Notion runs on Anthropic’s Claude — specifically Claude Opus 4.7 as of the January 2026 update. This is different from Microsoft Copilot (which uses OpenAI’s GPT models) and Google Workspace (which uses the Gemini family). Notion’s choice of Claude reflects an emphasis on reliable, safe agentic behavior for workflows that have write access to business databases.
What is the Notion External Agents API?
The External Agents API, launched with Notion 3.5 on May 13, 2026, lets teams bring any AI agent — including ones built internally or from partners like Claude, Codex, and Decagon — directly into their Notion workspace. These external agents can read and write to Notion databases with full context about the team’s data.
How is Notion different from Microsoft Copilot and Google Workspace AI?
Notion is database-first. Every piece of information in Notion is structured, typed, and queryable data — not documents. This means Notion agents can run precise database queries against your actual organizational data rather than inferring structure from prose documents. For teams that need AI to reliably operate on business data (not just search and summarize), this architectural difference is significant.
What are the real limitations of Notion Workers in the alpha?
Notion Workers runs in a 30-second sandbox with 128MB of memory and ephemeral storage. Network access is limited to an approved domain allowlist. Workers are created via the Notion control panel (3–5 minutes each). Long-running jobs — content pipelines, multi-site operations, image generation — won’t fit. The recommended pattern for serious workloads is Notion Workers as the trigger layer firing a signed POST to an external execution environment (like Google Cloud Run), with results written back to Notion databases via the Public API.