AI-generated editorial illustration — Vertex AI Imagen 4 Standard
About This Image
This image was generated by Google’s Vertex AI Imagen 4 model as the featured visual for We Tested Google Flow for Brand Asset Production. Every image in the Tygart Media visual library is AI-generated, converted to WebP for optimal performance, and enriched with IPTC/XMP metadata for search engine discoverability.
Technical Details
Model: Vertex AI Imagen 4 Standard (imagen-4.0-generate-001)
This image is one piece of a fully automated visual pipeline at Tygart Media. When a post needs a featured image, the system reads the article title and content, generates a contextually appropriate visual prompt, sends it to Google’s Imagen 4 model on Vertex AI, converts the output to WebP, injects IPTC/XMP metadata for SEO discoverability, uploads to WordPress, and sets it as the featured image — all without human intervention.
Every image in this gallery was made by the machine. Not selected from a stock library. Not commissioned from a designer. Fabricated on demand from the same knowledge system that produces the articles themselves.
AI-generated editorial illustration — Vertex AI Imagen 4 Standard
About This Image
This image was generated by Google’s Vertex AI Imagen 4 model as the featured visual for The SaaS Illusion Is Cracking: Why Custom Apps Now Cost Less Than Your Software Stack. Every image in the Tygart Media visual library is AI-generated, converted to WebP for optimal performance, and enriched with IPTC/XMP metadata for search engine discoverability.
Technical Details
Model: Vertex AI Imagen 4 Standard (imagen-4.0-generate-001)
This image is one piece of a fully automated visual pipeline at Tygart Media. When a post needs a featured image, the system reads the article title and content, generates a contextually appropriate visual prompt, sends it to Google’s Imagen 4 model on Vertex AI, converts the output to WebP, injects IPTC/XMP metadata for SEO discoverability, uploads to WordPress, and sets it as the featured image — all without human intervention.
Every image in this gallery was made by the machine. Not selected from a stock library. Not commissioned from a designer. Fabricated on demand from the same knowledge system that produces the articles themselves.
AI-generated editorial illustration — Vertex AI Imagen 4 Standard
About This Image
This image was generated by Google’s Vertex AI Imagen 4 model as the featured visual for The Loop Has to Go Both Ways. Every image in the Tygart Media visual library is AI-generated, converted to WebP for optimal performance, and enriched with IPTC/XMP metadata for search engine discoverability.
Technical Details
Model: Vertex AI Imagen 4 Standard (imagen-4.0-generate-001)
This image is one piece of a fully automated visual pipeline at Tygart Media. When a post needs a featured image, the system reads the article title and content, generates a contextually appropriate visual prompt, sends it to Google’s Imagen 4 model on Vertex AI, converts the output to WebP, injects IPTC/XMP metadata for SEO discoverability, uploads to WordPress, and sets it as the featured image — all without human intervention.
Every image in this gallery was made by the machine. Not selected from a stock library. Not commissioned from a designer. Fabricated on demand from the same knowledge system that produces the articles themselves.
AI-generated editorial illustration — Vertex AI Imagen 4 Standard
About This Image
This image was generated by Google’s Vertex AI Imagen 4 model as the featured visual for Split Brain Architecture: How One Person Manages 27 WordPress Sites Without an Agency. Every image in the Tygart Media visual library is AI-generated, converted to WebP for optimal performance, and enriched with IPTC/XMP metadata for search engine discoverability.
Technical Details
Model: Vertex AI Imagen 4 Standard (imagen-4.0-generate-001)
This image is one piece of a fully automated visual pipeline at Tygart Media. When a post needs a featured image, the system reads the article title and content, generates a contextually appropriate visual prompt, sends it to Google’s Imagen 4 model on Vertex AI, converts the output to WebP, injects IPTC/XMP metadata for SEO discoverability, uploads to WordPress, and sets it as the featured image — all without human intervention.
Every image in this gallery was made by the machine. Not selected from a stock library. Not commissioned from a designer. Fabricated on demand from the same knowledge system that produces the articles themselves.
If you run a content operation that serves multiple brands, you’ve probably looked at Google Flow and thought: could this actually replace part of our design pipeline? The image generation is impressive. The iteration feature — where you refine an image through successive prompts — is genuinely useful. But the question that matters for agency work isn’t “can it make pretty pictures.” It’s: can it maintain brand consistency across a production run?
We spent a morning running controlled experiments to find out. The results reshape how we think about AI image generation for client work.
What We Tested
We created a fictional coffee brand (“Summit Brew Coffee Company”) with a distinctive mountain-and-coffee-cup logo in black and gold. Then we pushed Flow’s iteration system through three scenarios that mirror real agency workflows:
Scenario 1: Brand persistence across applications. We took the logo from flat design → product mockup → merchandise collection → outdoor lifestyle shoot. Seven total iterations, each changing the context dramatically while asking the model to maintain the brand.
Scenario 2: Element burn-in. We deliberately introduced a red baseball cap, iterated with it for three consecutive generations, then tried to remove it. This simulates the common problem of “I showed the client a concept with X, they don’t want X anymore, but the AI keeps putting X back in.”
Scenario 3: Chain isolation. We started a completely separate iteration chain from a different logo variant within the same project. Does history from Chain A bleed into Chain B?
The Three Findings That Change Our Workflow
1. Brand Fidelity Is Surprisingly High — 9/10 Across 7 Iterations
The Summit Brew mountain icon, typography, and gold/black color scheme maintained recognizable consistency from flat logo all the way through to an outdoor campsite product shoot. Minor proportion drift in the icon (maybe 10%), but the brand was immediately identifiable in every single output. For mockup and concept work, this is production-ready fidelity.
2. Nothing Burns In Before 3 Iterations — Probably Closer to 5-8
The baseball cap was cleanly removable after appearing in three consecutive iterations. Both the cap and a coffee mug were stripped out with a single well-crafted removal prompt. This is huge for agency work — it means you can explore directions with clients, change your mind, and the AI will cooperate. The key is using explicit positive framing (“show ONLY the bag”) alongside negative instructions (“no hat, no cap”).
3. Iteration Chains Are Completely Isolated
This is the most operationally significant finding. Chain B had zero contamination from Chain A. No red caps, no coffee mugs, no campsite. The logo style from Chain B’s source image was preserved perfectly. Each image in your project grid has its own independent memory. The project is just an organizational container.
The Operational Playbook We’re Now Using
Based on these findings, here’s the workflow we’ve adopted for client brand asset production:
Step 1: Generate your anchor asset. Create the logo or hero image. Generate 4 variants, pick the best one.
Step 2: Keep chains short. 3-5 iterations maximum per chain. At this depth, everything remains controllable.
Step 3: Branch for each application. Logo → product mockup is one chain. Logo → social media banner is a new chain. Logo → billboard is a new chain. The isolation means each application gets a clean start with no baggage.
Step 4: Use Ingredients for cross-chain consistency. Flow’s @ referencing system lets you lock a brand asset as a reusable Ingredient. This is your AI brand guide — reference it in every new chain to maintain identity.
Step 5: Never fight the model past 5 iterations. If artifacts are persisting despite removal prompts, don’t iterate further. Save your best output, start a fresh chain from it, and you’ll have a clean slate.
What This Means for Agency Economics
Image generation in Flow is free (0 credits for Nano Banana 2). The iteration system is fast (20-30 seconds per batch of 4). And the brand consistency is high enough for mockup, concept, and internal review work. This doesn’t replace a senior designer for final deliverables, but it compresses the concepting and iteration phase from hours to minutes.
For agencies managing 10+ brands, the combination of chain isolation and Ingredient locking means you can run parallel brand pipelines without any risk of cross-contamination. That’s a workflow that didn’t exist six months ago.
The full technical white paper with detailed methodology is available upon request.
{
“@context”: “https://schema.org”,
“@type”: “Article”,
“headline”: “We Tested Google Flow for Brand Asset Production — Heres What Actually Works”,
“description”: “We ran controlled experiments on Google Flow’s iteration system to answer the question every agency needs answered: can AI maintain brand consistency acro”,
“datePublished”: “2026-04-03”,
“dateModified”: “2026-04-03”,
“author”: {
“@type”: “Person”,
“name”: “Will Tygart”,
“url”: “https://tygartmedia.com/about”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/tygart-media-logo.png”
}
},
“mainEntityOfPage”: {
“@type”: “WebPage”,
“@id”: “https://tygartmedia.com/google-flow-brand-asset-production-testing/”
}
}
Private jet charter represents the ultimate in luxury travel — bypassing commercial airports entirely for a seamless door-to-door experience. With hourly rates ranging from $3,000 for light jets to $15,000+ for ultra-long-range heavy aircraft, the private aviation industry generates over $30 billion annually in the United States alone. This photo gallery takes you inside the world of private jet charter — from the tarmac and cockpit to the luxury cabin and FBO terminal.
Private Jet Charter Photo Gallery
Ultra-luxury cabin: Hand-stitched leather, exotic wood veneer, and full champagne serviceState-of-the-art glass cockpit: Modern avionics suite enabling transcontinental flight capabilityCruising at 45,000 feet: Private jets fly above commercial traffic for faster, smoother flightsFixed Base Operator (FBO) private terminal — bypassing commercial airports entirelyOnboard bedroom suite on ultra-long-range aircraft — sleeping flat on transcontinental flightsCharter fleet: Light jets to heavy long-range aircraft available for immediate departureThe private jet experience: Door-to-door luxury with red carpet boarding and personal ground crew
Understanding Private Jet Categories
Private jets are classified into categories based on size, range, and cabin configuration. Very Light Jets (VLJs) like the Cessna Citation M2 carry 4-5 passengers up to 1,200 nautical miles. Light jets like the Phenom 300 accommodate 6-8 passengers with 2,000 nm range. Midsize jets like the Citation Latitude offer stand-up cabins for 8-9 passengers. Super-midsize aircraft like the Challenger 350 provide coast-to-coast range. Heavy jets like the Gulfstream G650 deliver transcontinental capability for 12-16 passengers. Ultra-long-range aircraft like the Global 7500 and Gulfstream G700 can fly 7,500+ nm nonstop — New York to Tokyo — with full bedroom suites, showers, and conference rooms.
The Private Jet Charter Experience
Charter passengers arrive at a Fixed Base Operator (FBO) — a private terminal with luxury lounges, concierge service, and direct tarmac access. There are no TSA security lines, no boarding groups, and no checked baggage restrictions. Passengers drive directly to their aircraft, with luggage loaded by ground crew. Most FBOs offer catering, ground transportation coordination, customs pre-clearance for international flights, and pet-friendly policies. The entire experience from car to cabin takes under 15 minutes — compared to the 2-3 hours typical of commercial air travel.
Frequently Asked Questions About Private Jet Charter
How much does it cost to charter a private jet?
Charter costs vary by aircraft category: Light jets run $3,000-$6,000 per flight hour, midsize jets cost $4,500-$8,000/hour, super-midsize aircraft range from $6,000-$10,000/hour, and heavy/ultra-long-range jets command $8,000-$15,000+ per hour. A New York to Miami trip on a midsize jet costs approximately $18,000-$28,000 one-way. Empty leg flights — when aircraft reposition without passengers — are available at 25-75% discounts.
How far in advance should you book a private jet?
Same-day charter is possible through the spot market, though availability and pricing are less favorable. Optimal pricing requires 1-2 weeks advance notice. Peak travel periods — holidays, Super Bowl, Aspen ski season, Art Basel — may require 30+ days. Jet card and membership programs guarantee availability within 24-48 hours at fixed rates regardless of market conditions.
What is an FBO terminal?
A Fixed Base Operator (FBO) is a private aviation facility at an airport providing services exclusively to private jet passengers and crew. Premier FBOs like Signature Flight Support, Atlantic Aviation, and Jet Aviation offer luxury lounges, conference rooms, concierge services, customs/immigration processing, crew rest areas, aircraft fueling and maintenance, and direct ramp access. Passengers bypass the commercial terminal entirely — driving directly to their aircraft on the tarmac.
How many passengers can a private jet carry?
Passenger capacity ranges from 4 seats on very light jets to 19 seats on ultra-long-range heavy aircraft. Light jets (Phenom 300, Citation CJ4) carry 6-8 passengers. Midsize jets (Citation Latitude, Learjet 75) carry 8-9. Super-midsize (Challenger 350, Citation Longitude) carry 9-12. Heavy jets (Gulfstream G650, Falcon 8X) carry 12-16. The largest ultra-long-range aircraft like the Global 7500 and Gulfstream G700 accommodate up to 19 passengers in configurations that include bedrooms, showers, and full dining areas.
{
“@context”: “https://schema.org”,
“@graph”: [
{
“@type”: “ImageGallery”,
“name”: “Private Jet Charter Photos u2014 Luxury Aviation Visual Guide”,
“description”: “Photo gallery of private jet charters featuring aircraft exteriors, luxury cabin interiors, cockpits, FBO terminals, bedroom suites, and VIP boarding experiences.”,
“url”: “https://tygartmedia.com/private-jet-charter-photos/”,
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”
},
“image”: [
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-tarmac-sunset.webp”,
“description”: “Sleek white private jet on tarmac at sunset with deployed stairs and golden light”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-luxury-cabin-interior.webp”,
“description”: “Luxury private jet cabin interior with cream leather seats, wood veneer, and champagne service”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-cockpit-night-avionics.webp”,
“description”: “Private jet cockpit at night with illuminated avionics displays and stars through windshield”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-above-clouds-flight.webp”,
“description”: “Private jet flying above dramatic cloud formations at high altitude with deep blue sky”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-fbo-terminal-lounge.webp”,
“description”: “Luxury FBO private terminal lounge with runway views, premium seating, and concierge service”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-bedroom-suite.webp”,
“description”: “Private jet bedroom suite with full-size bed, silk bedding, and ambient mood lighting”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-fleet-airport-ramp.webp”,
“description”: “Fleet of private jets parked on executive airport ramp with mountains in background”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-vip-boarding-red-carpet.webp”,
“description”: “VIP passengers boarding private jet via red carpet with luxury sedan and ground crew on tarmac”
}
]
},
{
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “How much does it cost to charter a private jet?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Private jet charter costs range from $3,000-$6,000 per hour for light jets (4-7 passengers) to $8,000-$15,000 per hour for heavy long-range jets (12-16 passengers). A coast-to-coast U.S. flight on a midsize jet costs approximately $25,000-$45,000 one-way.”
}
},
{
“@type”: “Question”,
“name”: “How far in advance should you book a private jet?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “While same-day booking is possible on the spot market, optimal pricing requires 1-2 weeks advance notice. Peak periods like holidays and major events may require 30+ days. Empty leg flights u2014 repositioning flights sold at 25-75% discounts u2014 are available with 1-7 days notice.”
}
},
{
“@type”: “Question”,
“name”: “What is an FBO terminal?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “A Fixed Base Operator (FBO) is a private aviation terminal at an airport that serves private jet passengers. FBOs provide luxurious lounges, concierge services, customs/immigration processing, aircraft fueling, and hangar services. Passengers drive directly to the aircraft, bypassing commercial terminals entirely.”
}
},
{
“@type”: “Question”,
“name”: “How many passengers can a private jet carry?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Private jet capacity varies by category: Very Light Jets (VLJs) carry 4-5 passengers, Light Jets carry 6-8, Midsize Jets carry 8-9, Super-Midsize carry 9-12, Heavy Jets carry 12-16, and Ultra-Long-Range aircraft carry 12-19 passengers with bedroom suites.”
}
}
]
},
{
“@type”: “Article”,
“headline”: “Private Jet Charter Photos u2014 Luxury Aviation Visual Guide”,
“author”: {
“@type”: “Organization”,
“name”: “Tygart Media”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”
},
“datePublished”: “2026-03-30”,
“image”: “https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-tarmac-sunset.webp”
}
]
}
Solar panel installation has become the fastest-growing segment of the U.S. energy market, with residential installations exceeding 1 million homes annually. The average system costs $15,000 to $35,000 before the 30% federal tax credit, delivering 25-30 years of clean energy and typical payback periods of 6-10 years. This comprehensive photo gallery documents every aspect of solar installation — from aerial views of completed rooftop arrays to the technical details of micro-inverters, battery storage, and thermal inspection.
Solar Panel Installation Photo Gallery
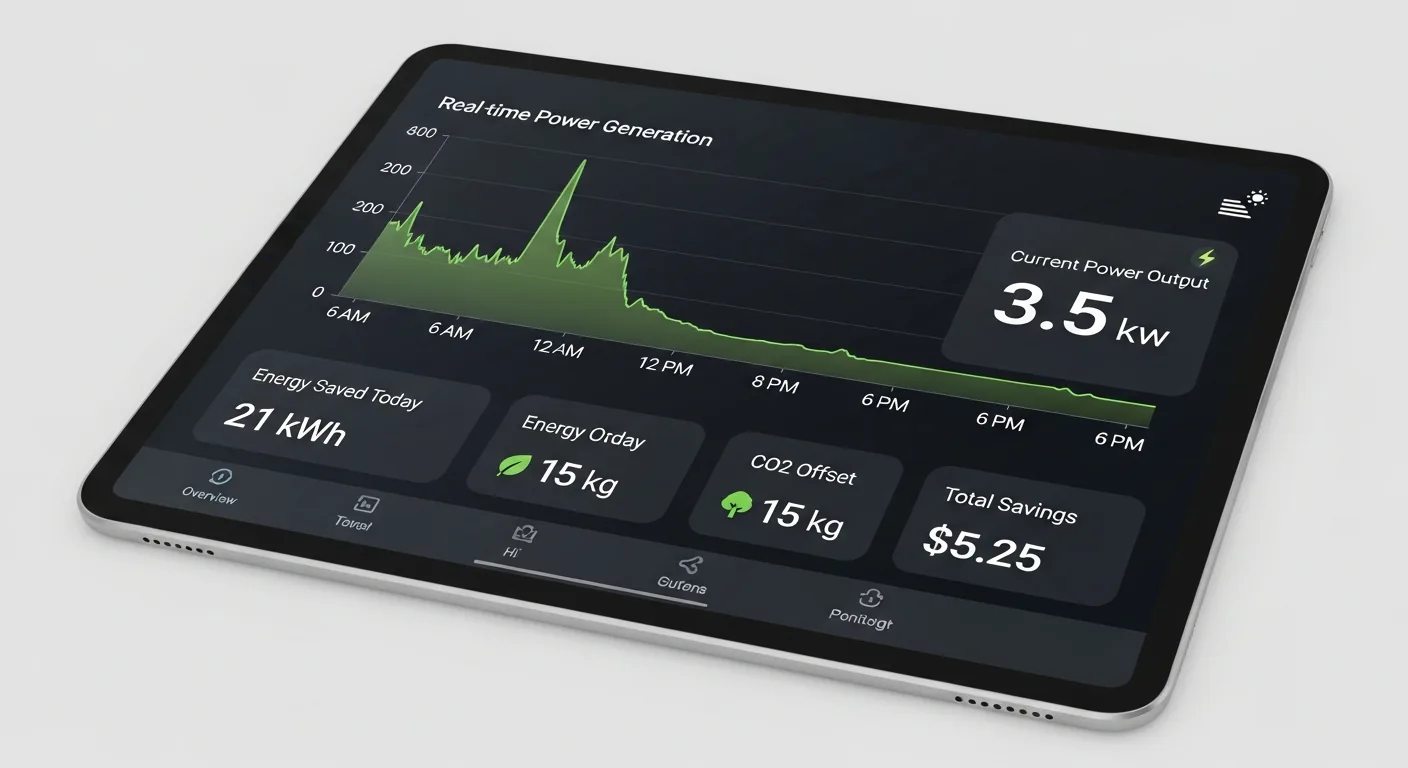
Professional installers securing photovoltaic panels to aluminum racking — proper safety equipment requiredUtility-scale solar farm generating megawatts of clean energy — the future of commercial power generationMicro-inverter and connector detail — the electrical backbone of a modern solar installationBattery storage integration paired with solar for 24/7 energy independenceThermal imaging inspection: Identifying underperforming cells and potential defects in solar arraysBefore and after: Modern all-black solar panels enhancing both energy production and curb appealReal-time solar monitoring: Tracking generation, consumption, and dollar savings from your installation
The Solar Installation Process
A professional solar installation follows a structured process: site assessment evaluates roof orientation, pitch, shading, and structural capacity; system design determines optimal panel placement using satellite imagery and shade analysis tools like Aurora Solar; permitting secures local building and electrical permits (typically 2-6 weeks); installation involves mounting racking systems, securing panels, running conduit, and connecting inverters (1-3 days); inspection by local building officials verifies code compliance; and interconnection with the utility company activates net metering and powers on the system. The total timeline from contract to activation averages 2-4 months.
Solar Technology: Panels, Inverters, and Battery Storage
Modern residential solar systems use monocrystalline silicon panels with efficiencies of 20-23%, producing 370-430 watts per panel. Inverter technology has evolved from single string inverters to microinverters (one per panel) and DC optimizers, which maximize output and enable panel-level monitoring. Battery storage systems like the Tesla Powerwall (13.5 kWh), Enphase IQ Battery (10.1 kWh), and Franklin WH (13.6 kWh) provide backup power and enable time-of-use arbitrage. The combination of solar panels and battery storage enables true energy independence — generating, storing, and consuming your own electricity 24/7.
Frequently Asked Questions About Solar Installation
How much do solar panels cost to install?
The average residential solar installation costs $15,000 to $35,000 before incentives, depending on system size and equipment quality. The federal Investment Tax Credit (ITC) reduces this by 30%, bringing net costs to $10,500-$24,500. Cost per watt installed ranges from $2.50 to $4.00. Premium panel brands like SunPower and REC command higher prices but offer superior warranties and efficiency.
How long does solar panel installation take?
Physical installation typically takes 1-3 days for a standard residential system. However, the complete process from signed contract to system activation — including engineering review, permitting, installation, inspection, and utility interconnection — takes 2-4 months in most markets. Permitting timelines vary significantly by jurisdiction.
Do solar panels work on cloudy days?
Yes. Solar panels generate electricity under cloud cover at 10-25% of rated capacity. Modern panels with half-cut cell technology and PERC (Passivated Emitter and Rear Contact) architecture perform significantly better in diffuse light than older poly-crystalline panels. Germany, one of the cloudiest countries in Europe, is also one of the world’s largest solar markets — proving that solar works effectively in less-than-ideal conditions.
How long do solar panels last?
Modern solar panels carry 25-30 year performance warranties guaranteeing at least 80-85% of original output at warranty end. Studies from NREL show most panels degrade at only 0.3-0.5% per year, meaning a panel producing 400W today will still produce 340-360W after 30 years. Panels continue generating power well beyond their warranty period. String inverters typically need replacement at 10-15 years ($1,500-$3,000), while microinverters carry 25-year warranties matching the panels.
{
“@context”: “https://schema.org”,
“@graph”: [
{
“@type”: “ImageGallery”,
“name”: “Solar Panel Installation Photos u2014 Complete Visual Guide”,
“description”: “Photo gallery of residential and commercial solar panel installations, equipment, monitoring systems, and maintenance.”,
“url”: “https://tygartmedia.com/solar-panel-installation-photos/”,
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”
},
“image”: [
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/residential-solar-panel-rooftop-aerial.webp”,
“description”: “Aerial view of residential solar panel array installed on modern home rooftop”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/solar-panel-installation-crew-rooftop.webp”,
“description”: “Solar panel installation crew mounting photovoltaic panels on residential roof with safety equipment”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/commercial-solar-farm-aerial-desert.webp”,
“description”: “Massive commercial solar farm with thousands of ground-mounted panels stretching across desert landscape”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/solar-panel-micro-inverter-wiring-detail.webp”,
“description”: “Close-up of solar panel micro-inverter and wiring connections during installation”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/solar-battery-storage-system.webp”,
“description”: “Home battery storage system mounted on garage wall next to electrical panel”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/solar-panel-thermal-inspection.webp”,
“description”: “Solar panel technician using thermal imaging camera to inspect for hot spots and defects”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/solar-panel-before-after-home.webp”,
“description”: “Before and after comparison of home with and without solar panel installation on roof”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/solar-energy-monitoring-dashboard.webp”,
“description”: “Solar energy monitoring dashboard showing real-time power generation and savings on tablet”
}
]
},
{
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “How much do solar panels cost to install?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “The average residential solar panel installation costs $15,000 to $35,000 before incentives. After the 30% federal Investment Tax Credit (ITC), the net cost drops to $10,500 to $24,500. Cost per watt ranges from $2.50 to $4.00 installed.”
}
},
{
“@type”: “Question”,
“name”: “How long does solar panel installation take?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Physical installation typically takes 1-3 days for residential systems. However, the full process from signed contract to power-on u2014 including permitting, inspection, and utility interconnection u2014 takes 2-4 months in most markets.”
}
},
{
“@type”: “Question”,
“name”: “Do solar panels work on cloudy days?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Yes, solar panels generate electricity on cloudy days, though at reduced output u2014 typically 10-25% of their rated capacity. Modern panels with half-cut cell technology and PERC architecture perform significantly better in low-light conditions than older panels.”
}
},
{
“@type”: “Question”,
“name”: “How long do solar panels last?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Modern solar panels carry 25-30 year performance warranties guaranteeing at least 80-85% of original output. Most panels continue generating power well beyond 30 years. Inverters typically need replacement at 10-15 years, costing $1,500-$3,000.”
}
}
]
},
{
“@type”: “Article”,
“headline”: “Solar Panel Installation Photos u2014 Complete Visual Guide”,
“author”: {
“@type”: “Organization”,
“name”: “Tygart Media”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”
},
“datePublished”: “2026-03-30”,
“image”: “https://tygartmedia.com/wp-content/uploads/2026/03/residential-solar-panel-rooftop-aerial.webp”
}
]
}
Penetration testing — also known as ethical hacking or pen testing — is a controlled cyberattack simulation conducted against an organization’s systems, networks, and applications to identify exploitable vulnerabilities before malicious actors do. This visual guide provides a comprehensive gallery of penetration testing environments, tools, methodologies, and deliverables used by cybersecurity professionals worldwide. With average engagement costs ranging from $10,000 to $100,000+ for enterprise assessments, penetration testing represents one of the highest-value services in the cybersecurity industry.
Penetration Testing Photo Gallery: Tools, Environments, and Methodologies
The following images document the complete penetration testing lifecycle — from the Security Operations Center where monitoring begins, through the ethical hacker’s workstation and toolkit, to the executive boardroom where findings are presented to stakeholders. Each image represents a critical phase of a professional penetration testing engagement.
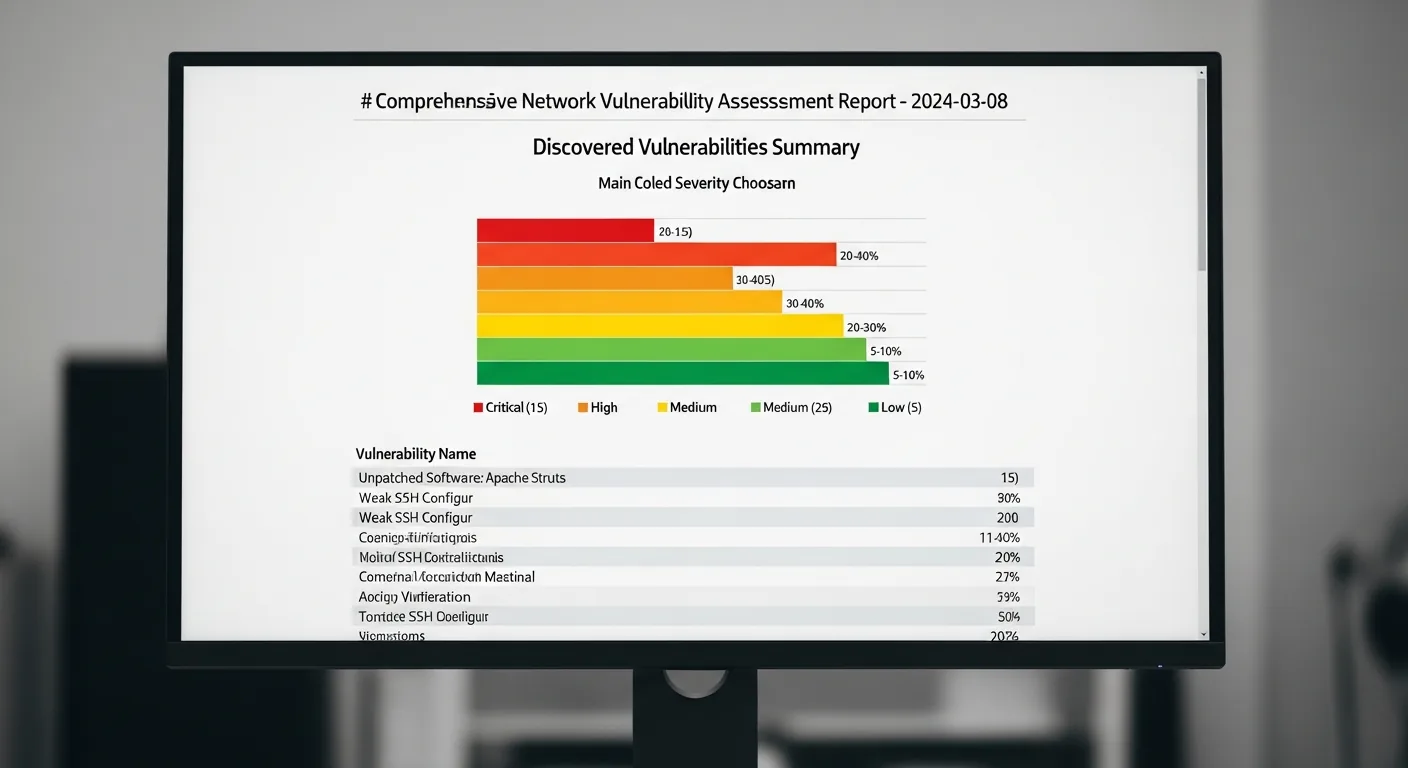
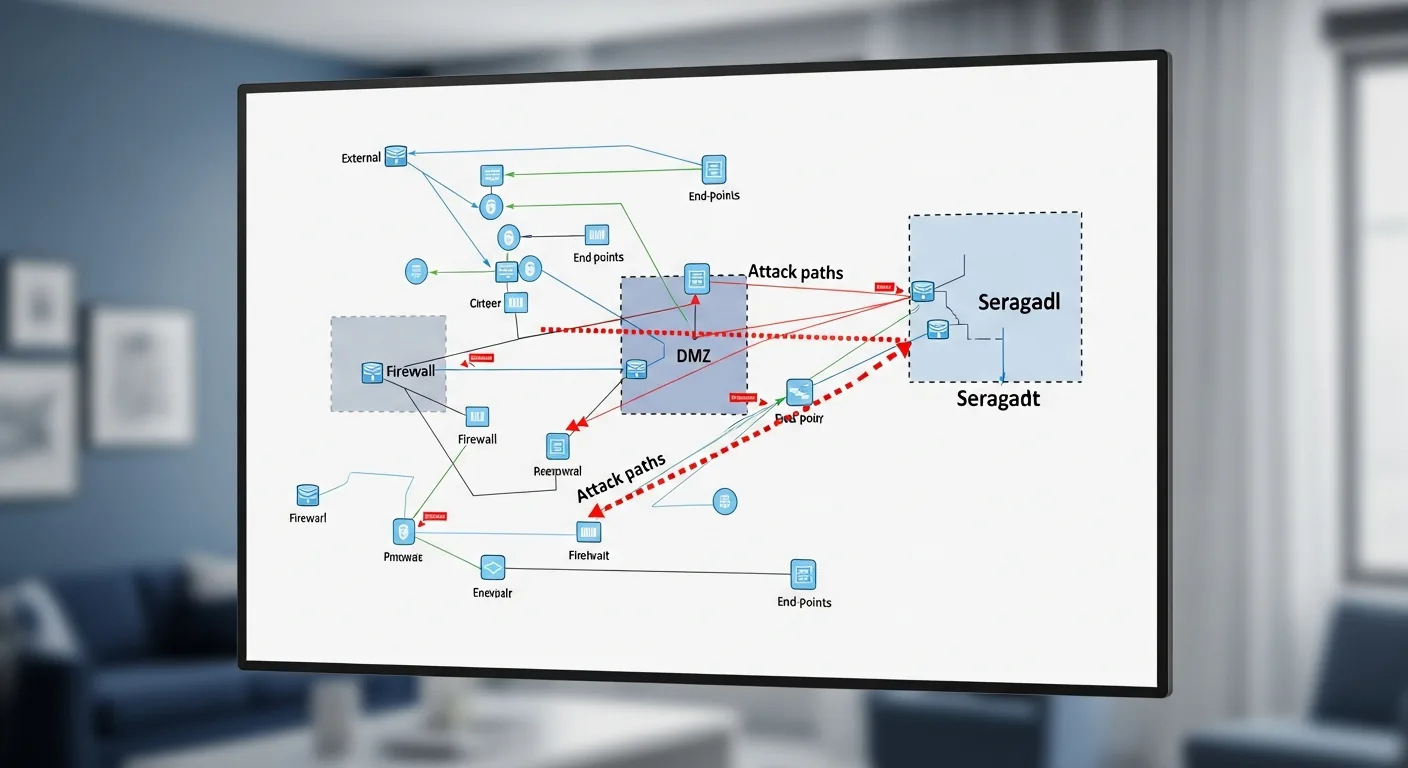
Penetration tester workstation running Kali Linux with active vulnerability scanning toolsVulnerability scan results with CVSS severity scoring — critical findings highlighted in redRed team vs blue team exercise: Simulating real-world attack and defense scenariosEnterprise server rack — a common target during network penetration testing engagementsNetwork topology with identified attack paths — mapping the route from perimeter to critical assetsProfessional penetration testing toolkit: WiFi Pineapple, USB implants, RFID cloner, and bypass toolsDelivering penetration test findings: Executive summary with risk matrix and remediation roadmap
The Five Phases of Penetration Testing
Professional penetration testing follows a structured methodology defined by frameworks like the PTES (Penetration Testing Execution Standard) and OWASP Testing Guide. The five phases are: Reconnaissance (passive and active information gathering about the target), Scanning (port scanning, vulnerability scanning, and service enumeration using tools like Nmap and Nessus), Exploitation (attempting to breach identified vulnerabilities using frameworks like Metasploit), Post-Exploitation (privilege escalation, lateral movement, and data exfiltration simulation), and Reporting (documenting findings with CVSS severity scores and remediation recommendations).
Red Team vs Blue Team: Adversarial Security Testing
Beyond traditional penetration testing, many organizations conduct red team engagements — extended adversarial simulations where an offensive team (red) attempts to breach the organization’s defenses while the defensive team (blue) works to detect and respond to the attacks in real time. Purple team exercises combine both perspectives, with the red team sharing techniques and the blue team improving detection capabilities. These exercises test not just technical controls but also the organization’s incident response procedures, employee security awareness, and communication protocols under pressure.
Essential Penetration Testing Tools and Equipment
A professional penetration tester’s arsenal includes both software and hardware tools. On the software side, Kali Linux serves as the primary operating system, bundling over 600 security tools including Burp Suite for web application testing, Metasploit for exploitation, Wireshark for network analysis, and John the Ripper for password cracking. Physical penetration testing adds hardware devices like the WiFi Pineapple for wireless attacks, USB Rubber Ducky for keystroke injection, Proxmark for RFID cloning, and traditional lock picks for physical access testing. The complete toolkit shown in this gallery represents approximately $5,000-$15,000 in equipment investment.
Frequently Asked Questions About Penetration Testing
How much does a penetration test cost?
Penetration testing costs vary significantly based on scope, complexity, and the type of assessment. A basic web application pen test typically ranges from $5,000 to $25,000. A comprehensive network penetration test for a mid-size enterprise costs $15,000 to $50,000. Red team engagements with physical testing, social engineering, and extended timelines can exceed $100,000. Organizations in regulated industries like healthcare (HIPAA), finance (PCI DSS), and government (FedRAMP) often require annual penetration testing as a compliance requirement.
What is the difference between a vulnerability scan and a penetration test?
A vulnerability scan is an automated process that identifies known vulnerabilities in systems using databases like the CVE (Common Vulnerabilities and Exposures) list — it finds potential weaknesses but does not attempt to exploit them. A penetration test goes further by having skilled security professionals actively attempt to exploit those vulnerabilities, chain multiple findings together, and demonstrate the real-world impact of a successful attack. Vulnerability scans cost $1,000-$5,000 and take hours; penetration tests cost $10,000-$100,000+ and take days to weeks.
How often should an organization conduct penetration testing?
Industry best practice and most compliance frameworks recommend penetration testing at least annually, with additional testing after significant infrastructure changes, application deployments, or security incidents. Organizations handling sensitive data should consider quarterly testing. PCI DSS requires annual penetration testing and retesting after significant changes. Many mature security programs implement continuous penetration testing programs that combine automated scanning with periodic manual assessments.
What certifications should a penetration tester hold?
The most respected penetration testing certifications include OSCP (Offensive Security Certified Professional), widely considered the gold standard due to its hands-on 24-hour exam; GPEN (GIAC Penetration Tester) from SANS; CEH (Certified Ethical Hacker) from EC-Council; and CREST CRT/CCT recognized internationally. For web application testing specifically, the OSWE (Offensive Security Web Expert) and BSCP (Burp Suite Certified Practitioner) are highly valued. When selecting a penetration testing firm, verify that their testers hold at minimum OSCP or equivalent hands-on certifications.
{
“@context”: “https://schema.org”,
“@graph”: [
{
“@type”: “ImageGallery”,
“name”: “Penetration Testing Photos u2014 Tools, Environments & Methodology Visual Guide”,
“description”: “Comprehensive photo gallery of penetration testing environments, ethical hacking tools, SOC monitoring setups, red team exercises, and vulnerability assessment processes.”,
“url”: “https://tygartmedia.com/penetration-testing-photos/”,
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”
},
“image”: [
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/penetration-testing-security-operations-center.webp”,
“description”: “Security Operations Center with multiple monitors displaying network threat detection dashboards”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/ethical-hacker-penetration-testing-workstation.webp”,
“description”: “Ethical hacker workstation with dual monitors running Kali Linux and network scanning tools”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/vulnerability-scan-report-penetration-test.webp”,
“description”: “Network vulnerability scan report showing color-coded severity levels and CVSS scores”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/red-team-blue-team-cybersecurity-exercise.webp”,
“description”: “Red team versus blue team cybersecurity exercise in a corporate war room with attack strategy whiteboard”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/server-rack-data-center-penetration-test-target.webp”,
“description”: “Server rack in data center with blinking LED status lights and organized ethernet cables”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/network-topology-attack-path-visualization.webp”,
“description”: “Network topology diagram showing attack paths, firewalls, and DMZ zones on a touchscreen display”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/penetration-testing-toolkit-equipment.webp”,
“description”: “Physical penetration testing toolkit including WiFi Pineapple, USB rubber ducky, lock picks, and RFID tools”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/penetration-test-executive-report-presentation.webp”,
“description”: “Cybersecurity executive presenting penetration test findings with risk matrix to corporate board room”
}
]
},
{
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “How much does a penetration test cost?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Basic web application pen tests range from $5,000 to $25,000. Comprehensive network penetration tests cost $15,000 to $50,000. Red team engagements can exceed $100,000.”
}
},
{
“@type”: “Question”,
“name”: “What is the difference between a vulnerability scan and a penetration test?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “A vulnerability scan is automated and identifies known weaknesses without exploiting them ($1,000-$5,000). A penetration test involves skilled professionals actively exploiting vulnerabilities to demonstrate real-world impact ($10,000-$100,000+).”
}
},
{
“@type”: “Question”,
“name”: “How often should an organization conduct penetration testing?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “At least annually per industry best practice and compliance frameworks, with additional testing after significant changes. PCI DSS requires annual testing. Mature programs implement continuous testing.”
}
},
{
“@type”: “Question”,
“name”: “What certifications should a penetration tester hold?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “OSCP (Offensive Security Certified Professional) is the gold standard. Other respected certs include GPEN, CEH, CREST CRT/CCT, OSWE, and BSCP.”
}
}
]
},
{
“@type”: “Article”,
“headline”: “Penetration Testing Photos u2014 Tools, Environments & Methodology Visual Guide”,
“description”: “Visual gallery of professional penetration testing environments, tools, and methodologies with full SEO and schema optimization.”,
“author”: {
“@type”: “Organization”,
“name”: “Tygart Media”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”
},
“datePublished”: “2026-03-30”,
“image”: “https://tygartmedia.com/wp-content/uploads/2026/03/penetration-testing-security-operations-center.webp”
}
]
}
Water damage restoration is one of the most critical services in property management and homeownership. Whether caused by burst pipes, flooding, roof leaks, or appliance failures, water damage can devastate residential and commercial properties within hours. This curated gallery of water damage photos documents every stage — from initial flooding to professional restoration — providing a visual reference for homeowners, insurance adjusters, property managers, and restoration professionals.
Water Damage Photo Gallery: From Disaster to Restoration
The following images illustrate the most common types of water damage encountered in residential and commercial properties, along with the professional restoration equipment and processes used to remediate them. Each image is optimized in WebP format for fast loading.
Flooded basement showing the devastating impact of water intrusion on stored belongingsCeiling water damage showing extensive staining and structural compromise from leak aboveProfessional restoration crew extracting standing water using industrial-grade equipmentMold growth on drywall resulting from untreated water damage and persistent moistureProfessional drying setup: Air movers and dehumidifiers restoring moisture-damaged subfloorLarge-scale commercial drying operation with industrial dehumidifiers and air moversBurst copper pipe actively flooding a kitchen — the most common cause of indoor water damage
Understanding Water Damage Categories and Classes
The Institute of Inspection, Cleaning and Restoration Certification (IICRC) classifies water damage into three categories based on contamination level and four classes based on evaporation rate. Category 1 involves clean water from supply lines, Category 2 involves gray water with biological contaminants, and Category 3 involves black water from sewage or flooding. Understanding these distinctions is essential for proper remediation — the wrong approach can lead to persistent mold growth, structural compromise, and health hazards.
Common Causes of Water Damage Shown in This Gallery
The images above document the most frequently encountered causes of indoor water damage: burst pipes (responsible for an estimated 250,000 insurance claims annually in the United States), basement flooding from groundwater intrusion or sump pump failure, ceiling leaks from roof damage or plumbing failures in upper floors, and mold growth resulting from unaddressed moisture. Professional restoration crews deploy industrial-grade equipment including commercial air movers, LGR dehumidifiers, and moisture monitoring systems to systematically dry affected structures to IICRC S500 standards.
The Water Damage Restoration Process
Professional water damage restoration follows a systematic protocol: emergency water extraction removes standing water using truck-mounted or portable extractors; structural drying deploys air movers and dehumidifiers in calculated patterns based on psychrometric principles; moisture monitoring tracks progress with pin-type and pinless meters until materials reach acceptable moisture content; and antimicrobial treatment prevents secondary damage from mold colonization. The entire process typically takes 3-5 days for residential properties and 5-10 days for commercial spaces, depending on the severity and class of water damage.
Frequently Asked Questions About Water Damage
How quickly does mold grow after water damage?
Mold can begin colonizing damp surfaces within 24 to 48 hours after water exposure. This is why the IICRC recommends beginning water extraction within the first hour of discovery and having professional drying equipment in place within 24 hours. Visible mold growth typically appears within 3-7 days on porous materials like drywall, carpet padding, and wood framing if moisture is not properly addressed.
Does homeowners insurance cover water damage restoration?
Most standard homeowners insurance policies cover sudden and accidental water damage — such as burst pipes, appliance malfunctions, and accidental overflow. However, damage from gradual leaks, lack of maintenance, or external flooding typically requires separate coverage. The average water damage insurance claim in the United States ranges from $7,000 to $12,000, though catastrophic events can exceed $50,000. Document all damage thoroughly with photographs before remediation begins.
What does water damage restoration cost?
Water damage restoration costs vary based on the category, class, and square footage affected. Category 1 clean water extraction in a single room typically ranges from $1,000 to $4,000. Full-home restoration involving Category 3 contamination, mold remediation, and structural repairs can range from $10,000 to $50,000+. Most restoration companies offer free inspections and work directly with insurance carriers to manage the claims process.
Can water-damaged hardwood floors be saved?
In many cases, hardwood floors can be salvaged if drying begins within 24-48 hours. Professional restoration technicians use specialized hardwood floor drying mats and bottom-up drying techniques that force warm, dry air through the floorboards. However, if cupping, buckling, or delamination has progressed significantly, replacement may be the only option. Engineered hardwood is generally more difficult to salvage than solid hardwood due to its layered construction.
{
“@context”: “https://schema.org”,
“@graph”: [
{
“@type”: “ImageGallery”,
“name”: “Water Damage Restoration Photos u2014 Complete Visual Guide”,
“description”: “Comprehensive photo gallery documenting water damage in residential and commercial properties, from initial flooding to professional restoration. Includes burst pipes, flooded basements, ceiling damage, mold growth, and industrial drying equipment.”,
“url”: “https://tygartmedia.com/water-damage-restoration-photos/”,
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”
},
“image”: [
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/water-damage-flooded-living-room.webp”,
“description”: “Severe water damage in residential living room with flooded hardwood floors and waterlogged furniture”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/flooded-basement-water-damage.webp”,
“description”: “Flooded residential basement with standing water and damaged belongings”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/ceiling-water-damage-stain.webp”,
“description”: “Water-damaged ceiling with large brown stain and sagging drywall ready to collapse”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/water-damage-restoration-crew-extraction.webp”,
“description”: “Water damage restoration crew performing water extraction with industrial equipment”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/water-damage-mold-growth-drywall.webp”,
“description”: “Black mold growth on drywall from untreated water damage showing moisture stains”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/water-damage-drying-process.webp”,
“description”: “Water damage restoration drying setup with industrial air movers on exposed subfloor”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/commercial-water-damage-drying-equipment.webp”,
“description”: “Commercial water damage restoration drying setup with industrial air movers and dehumidifiers”
},
{
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/2026/03/burst-pipe-water-damage-kitchen.webp”,
“description”: “Burst pipe causing active water damage in kitchen with water spraying from cracked pipe”
}
]
},
{
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “How quickly does mold grow after water damage?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Mold can begin colonizing damp surfaces within 24 to 48 hours after water exposure. Visible mold growth typically appears within 3-7 days on porous materials like drywall, carpet padding, and wood framing if moisture is not properly addressed.”
}
},
{
“@type”: “Question”,
“name”: “Does homeowners insurance cover water damage restoration?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Most standard homeowners insurance policies cover sudden and accidental water damage such as burst pipes and appliance malfunctions. Damage from gradual leaks or external flooding typically requires separate coverage. The average claim ranges from $7,000 to $12,000.”
}
},
{
“@type”: “Question”,
“name”: “What does water damage restoration cost?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Category 1 clean water extraction in a single room typically ranges from $1,000 to $4,000. Full-home restoration involving Category 3 contamination can range from $10,000 to $50,000+.”
}
},
{
“@type”: “Question”,
“name”: “Can water-damaged hardwood floors be saved?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “In many cases, hardwood floors can be salvaged if drying begins within 24-48 hours using specialized hardwood floor drying mats and bottom-up drying techniques.”
}
}
]
},
{
“@type”: “Article”,
“headline”: “Water Damage Restoration Photos u2014 Complete Visual Guide”,
“description”: “Comprehensive photo gallery of water damage scenarios and professional restoration processes. AI-generated images optimized for web.”,
“author”: {
“@type”: “Organization”,
“name”: “Tygart Media”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”
},
“datePublished”: “2026-03-30”,
“image”: “https://tygartmedia.com/wp-content/uploads/2026/03/water-damage-flooded-living-room.webp”
}
]
}
We built an enterprise-grade marketing automation stack that costs less than $50/month using open-source AI, free API tiers, and Google Cloud free credits. If you’re a small business or bootstrapped startup, you don’t need to justify expensive tools.
Total cost: $47/month for production infrastructure
The AI Layer: Ollama + Self-Hosted Models Ollama lets you run open-source LLMs locally (or on cheap cloud instances). We run Mistral 7B (70 billion parameters, strong reasoning) on a small Cloud Run container.
Cost: $8/month (vs. $50+/month for Claude API) Tradeoff: Slightly slower (3-4 second latency vs. <1 second), less sophisticated reasoning (but still good)
What it’s good for: – Content summarization – Data extraction – Basic content generation – Classification tasks – Brainstorming outlines
What it struggles with: – Complex multi-step reasoning – Code generation – Nuanced writing
Our approach: Use Mistral for 60% of tasks, Claude API (paid) for the 40% that really need it.
The Data Layer: Free API Tiers DataForSEO Free Tier: – 5 free API calls/day – Useful for: one keyword research query per day – For more volume, pay per API call (~$0.01-0.02)
We use the free tier for daily keyword research, then batch paid requests on Wednesday nights when it’s cheapest.
NewsAPI Free Tier: – 100 requests/day – Get news for any topic – Useful for: building news-based content calendars, trend detection
We query trending topics daily (costs nothing) and surface opportunities.
SerpAPI Free Tier: – 100 free searches/month – Google Search API access – Useful for: SERP analysis, featured snippet research
We budget 100 searches/month for competitive analysis.
The Infrastructure: Google Cloud Free Tier – Cloud Run: 2 million requests/month free (more than enough for small site) – Cloud Storage: 5GB free storage – Cloud Logging: 50GB logs/month free – Cloud Scheduler: unlimited free jobs – Cloud Tasks: unlimited free queue – BigQuery: 1TB analysis/month free
This covers: – Hosting your WordPress instance – Running automation scripts – Logging everything – Analyzing traffic patterns – Scheduling batch jobs
The WordPress Setup – WordPress.com free tier: Start free, upgrade as you grow – OR: Self-host on Google Cloud ($15/month for small VM) – Open-source plugins: Jetpack (free features), Akismet (free tier), WP Super Cache (free)
We use self-hosted on GCP because we want plugin control, but WordPress.com free is perfectly viable for starting out.
The Analytics: Plausible Free Tier – 50K pageviews/month free – Privacy-focused (no cookies, no tracking headaches) – Clean, readable dashboards
Cost: Free (or $10/month if you exceed 50K) Tradeoff: Less detailed than Google Analytics, but you don’t need detail at the beginning
The Automation Layer: Zapier Free Tier** – 5 zaps (automations) free – Each zap can trigger actions across 2,000+ services
Examples of free zaps: 1. New WordPress post → send to Buffer (post to social) 2. New lead form submission → create Notion record 3. Weekly digest → send to email list 4. Twitter mention → Slack notification 5. New competitor article → Google Sheet (tracking)
Cost: Free (or $20/month for unlimited zaps) We use 5 free zaps for core workflows, then upgrade if we need more.
The CI/CD: GitHub Actions** – Unlimited free CI/CD for public repositories – Run scripts on schedule (content generation, data analysis) – Deploy updates automatically
We use GitHub Actions to: – Generate daily content briefs (runs at 6am) – Analyze trending topics (runs at 8am) – Summarize competitor content (runs nightly) – Publish scheduled posts (runs at optimal times)
Example: The Free Marketing Stack In Action Daily workflow (costs $0): 1. GitHub Actions triggers at 6am (free) 2. Queries DataForSEO free tier for trending keywords (free) 3. Queries NewsAPI for trending topics (free) 4. Passes data to Mistral on Cloud Run ($.0005 per call) 5. Mistral generates 3 content ideas and a brief ($.001 total) 6. Brief goes to Notion (free tier) 7. When you publish, WordPress post triggers Zapier (free) 8. Zapier sends to Buffer (free tier posts 5 posts/day) 9. Buffer posts to Twitter, LinkedIn, Facebook (free Buffer tier)
The Cost Breakdown – Google Cloud ($300 credit = first 10 months): $0 – After credit: $15-30/month (small VM) – DataForSEO free tier: $0 – WordPress self-hosted or free: $0-15/month – Plausible: $0 (free tier) – Zapier: $0 (free tier) – Ollama/Mistral: $0 (self-hosted)
First year: ~$180 (almost all Google Cloud credit) Year 2 onwards: ~$45-60/month
When To Upgrade When you have paying customers or real revenue (not “I want to scale”, but “I have actual income”): – Upgrade to Claude API (adds $50-100/month) – Upgrade to Zapier paid ($20/month for unlimited) – Upgrade to Plausible paid ($10/month) – Consider paid DataForSEO plan ($100/month)
But by then you have revenue to cover it.
The Advantage** Most bootstrapped founders tell themselves “I can’t start without expensive tools.” That’s a limiting belief. You can build a sophisticated marketing stack for nearly free.
What expensive tools give you: convenience and slightly better performance. What free tools give you: legitimacy and survival on limited budget.
The Tradeoff Philosophy – On LLM quality: Use Mistral (90% as good, 1/5 the cost) – On API quotas: Use free tiers aggressively, pay for specific high-volume operations – On infrastructure: Use free cloud tiers for 6+ months, upgrade when you have revenue – On automation: Use Zapier free tier, build custom automations later if you need more
The Takeaway** You don’t need a $3K/month marketing stack to start. You need understanding of what each tool does, free tiers of multiple services, and strategic thinking about where to spend when you have money.
Build on free. Graduate to paid only when you have revenue or specific bottlenecks that free tools can’t solve.
{
“@context”: “https://schema.org”,
“@type”: “Article”,
“headline”: “The $0 Marketing Stack: Open Source AI, Free APIs, and Cloud Credits”,
“description”: “Build an enterprise marketing stack for $0 using open-source AI, free API tiers, and Google Cloud credits. Here’s exactly what we use.”,
“datePublished”: “2026-03-30”,
“dateModified”: “2026-04-03”,
“author”: {
“@type”: “Person”,
“name”: “Will Tygart”,
“url”: “https://tygartmedia.com/about”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/tygart-media-logo.png”
}
},
“mainEntityOfPage”: {
“@type”: “WebPage”,
“@id”: “https://tygartmedia.com/the-0-marketing-stack-open-source-ai-free-apis-and-cloud-credits/”
}
}




![Private Jet Charter Photos — Luxury Aviation Visual Guide [2026]](https://tygartmedia.com/wp-content/uploads/2026/03/private-jet-tarmac-sunset.webp)







![Solar Panel Installation Photos — Complete Visual Guide [2026]](https://tygartmedia.com/wp-content/uploads/2026/03/residential-solar-panel-rooftop-aerial.webp)






![Penetration Testing Photos — Tools, Environments & Methodology Visual Guide [2026]](https://tygartmedia.com/wp-content/uploads/2026/03/penetration-testing-security-operations-center.webp)





![Water Damage Restoration Photos — Complete Visual Guide [2026]](https://tygartmedia.com/wp-content/uploads/2026/03/water-damage-flooded-living-room.webp)







