By Will Tygart
· Practitioner-grade
· From the workbench
Origin note: This started as a half-formed thought — “what if my second brain is what makes my Claude work so well, and what if I could let other people rent it?” The article below is the honest answer to that question, including the parts that argue against doing it.
The Observation That Started It
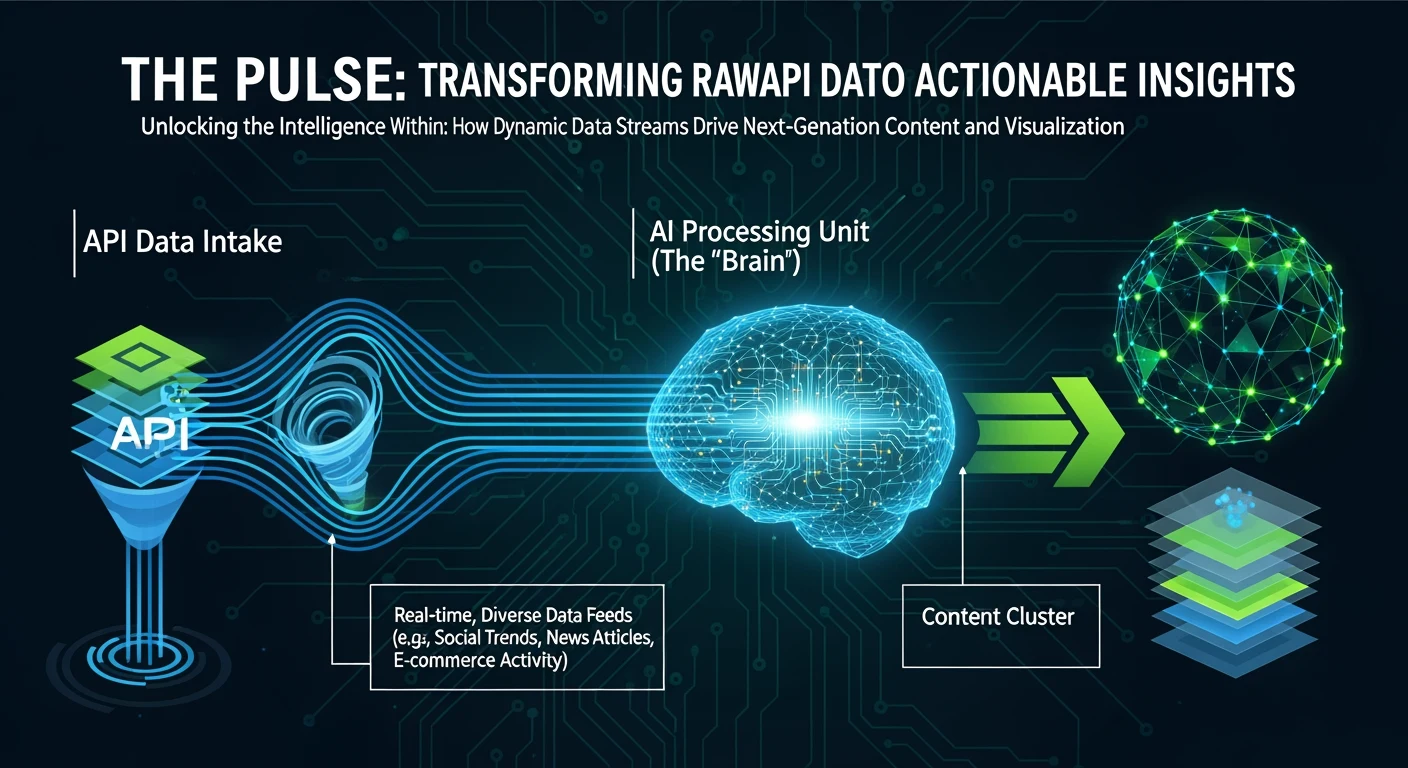
If you spend enough time building an operational stack on top of Claude — skills, Notion databases, retrieval pipelines, project knowledge, accumulated SOPs — you start to notice something strange. Your Claude does not just answer better than a fresh Claude. It moves better. It picks the right tool the first time. It remembers patterns from work you did six months ago on a different client. It improvises in ways that look almost like learning, even though the underlying model has not changed at all.
The model is the same. The context is doing the work.
That observation leads to an obvious question: if a curated context layer is what separates a useful AI from a frustrating one, could you sell access to your context layer? Not the model, not the prompts, not the chat interface — just the accumulated patterns, conventions, and operational wisdom, exposed as an API that any other AI workflow could pull from. Call it “Will’s Second Brain” or anything else. The pitch is: connect this to whatever you are building, and somehow it just works better. You will not always know why. That is part of the value.
This article walks through whether that is actually a good idea, what it would cost, what the conversion math looks like, what the legal exposure is, and where the real moat would have to come from.
The Category Already Exists (And That Is Mostly Good News)
The “memory layer for AI agents” category is real and growing fast. Mem0, which is probably the most visible player, raised a $24M Series A in October 2025 and reports more than 47,000 GitHub stars on its open-source SDK. Their pitch is essentially the one above: instead of stuffing the entire conversation history into every LLM call, route through a memory layer that retrieves only the relevant context. They claim around 90% lower token usage and 91% faster responses compared to full-context approaches. Their pricing tiers run from a free hobby plan (10K memories, 1K retrieval calls per month) to $19/month Starter to $249/month Pro to custom enterprise pricing.
Letta, formerly MemGPT, takes a different approach — it is a full agent runtime built around tiered memory (core, recall, archival) that mirrors how operating systems manage RAM and disk. Zep and its Graphiti engine focus on temporal knowledge graphs. SuperMemory bundles memory and RAG with a generous free tier. Hindsight publishes benchmark results claiming 91.4% on LongMemEval versus Mem0’s 49.0%, and offers all four retrieval strategies on its free tier. LangMem ships with LangGraph for teams already on that stack. AWS has Bedrock AgentCore Memory as the managed equivalent.
The good news in all of that: the category is validated. Buyers exist. Pricing precedents exist. The bad news: you are not going to win on infrastructure. You are not going to out-engineer a YC-backed team with $24M in funding and 47K stars. If you enter this space, you have to enter on a different axis entirely.
Where The Real Moat Would Be
The moat is not the storage. The moat is what is in the storage.
Mem0, Letta, and the rest sell empty memory layers. You bring the data. The promise is: if you put your facts in here, retrieval will be fast and cheap. That is a real value proposition, but it is a tooling pitch, not a knowledge pitch. The customer still has to build the knowledge themselves.
A second-brain-as-a-service offering would sell a pre-loaded memory layer. Not “here is a fast retrieval system,” but “here is a retrieval system that already knows how an AI-native content agency thinks about WordPress, SEO, GEO, AEO, taxonomy architecture, content refresh strategy, hub-and-spoke linking, Notion command center design, GCP publishing pipelines, and the operational lessons from running 27 client sites.” That is not a tooling product. That is consulting wisdom packaged as middleware.
The closest analogies are not Mem0 or Letta. They are things like:
- Cursor’s index of best practices baked into its autocomplete — the tool ships with an opinion about what good code looks like, and that opinion is the product.
- Linear’s opinionated workflows — the value is not the database, it is the prescribed way of working that the database enforces.
- 37signals’ Shape Up methodology being sold as a book — accumulated operational wisdom packaged as a product separate from the consulting practice.
The “second brain as an API” pitch is closer to Shape Up than to Mem0. The technical layer is just the delivery mechanism.
The Economics: Cheaper Than You Think, Harder Than You Think
Per-query costs for serving a RAG API are genuinely low. A typical retrieval call against a vector store runs somewhere in the range of fractions of a cent to a few cents depending on embedding model, vector store, and how many chunks you return. If you self-host on GCP using Cloud Run, BigQuery, and Vertex AI embeddings, marginal serving cost per query is negligible at small scale and only becomes meaningful at thousands of queries per minute.
The cost problems are not the queries. They are:
- Free trial abuse. Developer-facing API products with free trials get hammered. Bots, scrapers, people running benchmarks against you for blog posts, competitors testing your retrieval quality. If you offer any free tier without a credit card on file, expect a meaningful percentage of total traffic to be abuse. Hard rate limits and required payment methods from day one are not optional.
- Support load. Even a “just connect this and it works” product generates support tickets. Integration questions, schema confusion, “why did it return X when I asked Y,” “how do I cite this in my own product.” For a single operator, support load is the actual scaling constraint, not infrastructure.
- Conversion math. Free-trial-to-paid conversion for self-serve developer tools typically runs in the 2% to 5% range, with some outliers higher and many lower. A trial that converts at 2% needs roughly 50 trial signups per paying customer. If your trial is generous and your conversion is on the low end, you can spend more on serving free users than you earn from paid ones, especially in early months when paying user count is small.
None of this kills the idea. It just means the business case has to be built on top of realistic assumptions, not aspirational ones.
The Scrubbing Problem (This Is The Scariest Part)
An accumulated operational knowledge base built from real client work is, by definition, contaminated with information that cannot leave the building. Client names. Service URLs. App passwords. Internal strategy documents. Competitor analysis. Personal references. Names of contractors and partners. Slack-style observations about which clients are easy to work with and which are not. Pricing conversations. Things a client said in a meeting.
“I will scrub the data before I expose it” is a sentence that gets people sued. The problem is that scrubbing, done as a filter on top of live data, always misses things. You build a regex for client names, but you forget a client was referenced obliquely in a footnote. You strip URLs, but a screenshot or a code example contains a domain. You remove credentials, but an old version of a SOP still has an example token in it. Filters are 95% solutions to a problem that needs a 100% solution, because the failure mode of the missing 5% is “client finds their internal information being served to a stranger via your API.”
The right architecture is not a filter. It is a clean room.
That means a separate knowledge base, built from scratch, that contains only the patterns, conventions, and methodology — never the source material it was extracted from. You read your accumulated work, you write generalized lessons by hand or with heavy review, and those generalized lessons become the product. The production knowledge base never touches the serving knowledge base. There is an air gap, not a pipeline.
This is more work than the “scrub and ship” approach. It is also the only version that does not end in a lawsuit.
Liability Exposure
The moment “Will’s Second Brain” is connected to someone else’s workflow, three new liability vectors open up:
- Bad output causes a bad decision. Customer uses your API to generate strategy, follows the strategy, loses money, blames you. Mitigated by ToS, liability caps, and clear disclaimers that the service is informational and not professional advice.
- Hallucinated facts get cited as authoritative. Your knowledge base says something confident, customer publishes it, the something is wrong, customer’s audience holds them responsible. Mitigated by disclaimers and by being conservative about what gets included in the seed data.
- Your contaminated data ends up in front of the wrong eyes. See previous section. Mitigated by the clean-room architecture, not by promises.
The minimum legal infrastructure to launch is: an LLC, a Terms of Service with clear liability caps, a Privacy Policy, errors and omissions insurance, and ideally a separate entity that owns the product so the consulting business is shielded if the product business gets sued. None of these are expensive individually. All of them are necessary together.
The Loss Leader Question
One framing of the idea is: do not try to make money from it directly. Give it away. Let it serve as the most aggressive top-of-funnel content marketing asset Tygart Media has ever shipped. Every developer who connects “Will’s Second Brain” to their workflow becomes aware of Tygart Media. Some fraction of them will eventually need the consulting practice that the second brain was extracted from.
This is a much more defensible version of the idea, for three reasons:
- It removes the trial conversion math from the critical path. You are not optimizing for paid signups. You are optimizing for awareness and mindshare.
- It removes most of the support burden. Free tools have lower customer expectations. “It is free, here is the docs page” is a complete answer in a way that “you are paying $19 a month, please help me debug my integration” is not.
- It changes the liability story. Free tools used at the user’s own risk have a much easier time enforcing liability caps than paid services do.
The cost side of a free version is real but manageable. Hard rate limits, required signup with a real email address (for the funnel, not the billing), aggressive abuse detection, and serving costs absorbed as a marketing line item rather than a COGS line item. A few hundred dollars a month of GCP spend is cheaper than most paid ad campaigns and probably reaches more qualified people.
Verdict
The idea is good. The business is hard. The two are not the same thing.
The version that probably works is the loss-leader version: a free, rate-limited, clean-room knowledge API marketed as a top-of-funnel asset for the consulting practice, built from a hand-curated knowledge base that never touches client data, wrapped in a basic legal entity with a real ToS and E&O insurance. The version that probably does not work is the standalone subscription business with a free trial, because the trial economics, the support load, and the liability surface area are all more hostile than they look from the outside.
The thing worth building first is not the API. It is the clean-room knowledge base. If you can hand-write 100 generalized operational patterns from the existing stack, in a way that contains zero client-specific information and reads as standalone wisdom, you have proven the product is possible. If you cannot — if every pattern keeps wanting to reference a specific client situation to make sense — then the wisdom is not yet abstract enough to package, and the right move is to keep accumulating and revisit in six months.
Either way, the question that started this is the right question. Context is doing more work in modern AI than most people realize, and someone is going to figure out how to sell curated context as a product. It might as well be the operator who already has the most interesting context to sell.
Reference Data and Knowledge Node Notes
This section exists to make this article more useful as a knowledge node when scanned later. It contains the underlying market data, pricing references, and structural notes that informed the analysis above.
Memory Layer Market Snapshot (2026)
- Mem0: $24M Series A October 2025 (Peak XV, Basis Set Ventures). 47K+ GitHub stars. Apache 2.0 open source. Pricing: free Hobby (10K memories, 1K retrieval calls/month), $19 Starter (50K memories), $249 Pro (unlimited, graph memory, analytics), custom Enterprise. Claims 90% token reduction, 91% faster, +26% accuracy on LOCOMO benchmark vs OpenAI Memory. SOC 2, HIPAA available. Independent evaluation: 49.0% on LongMemEval.
- Letta (formerly MemGPT): Full agent runtime, not just memory layer. Three-tier OS-inspired architecture (core, recall, archival). Self-editing memory where agents decide what to store. Apache 2.0, ~21K GitHub stars. Python-only SDK. Best for new agent builds, not for adding memory to existing stacks.
- Zep / Graphiti: Temporal knowledge graphs. Strongest option for queries that need to reason about how facts changed over time. Reportedly scores 15 points higher than Mem0 on LongMemEval temporal subtasks.
- Hindsight: MIT licensed. Claims 91.4% on LongMemEval. All retrieval strategies (graph, temporal, keyword, semantic) available on free tier including self-hosted.
- SuperMemory: Bundled memory + RAG. Closed source. Generous free tier. Small API surface.
- LangMem: Memory tooling for LangGraph. Three memory types: episodic, semantic, procedural (agents updating their own instructions). Free, open source. Requires LangGraph.
- Bedrock AgentCore Memory: AWS managed equivalent. Out-of-the-box short-term and long-term memory.
Conversion Rate Reference Numbers
- Self-serve developer tool free trial → paid conversion: typically 2-5%, with B2B SaaS averages around 14-25% across all categories but developer tools tend to be lower because the audience is more skeptical and self-sufficient.
- Freemium to paid conversion (no trial, just free tier): typically 1-4%.
- Required credit card on free trial: roughly 2x conversion rate vs no card required, but 50-75% lower trial signup rate. Net result is usually higher quality but lower quantity.
Cost Reference Numbers (GCP, 2026)
- Vertex AI text embedding (gecko-003 or similar): roughly $0.000025 per 1K characters. A typical 500-word document chunk costs less than $0.0001 to embed.
- BigQuery vector search: storage is cheap, queries scale with the size of the result set. A retrieval against 100K vectors returning top-10 typically costs well under a cent.
- Cloud Run serving costs: minimum-instance-zero deployments cost nothing at idle. Per-request cost for a typical retrieval API is a fraction of a cent including CPU time and egress.
- Realistic monthly serving cost for a free, rate-limited “second brain” API at modest usage (say, 100 active users averaging 50 queries per day): probably $50-200/month total infrastructure.
The Clean Room Architecture (Recommended Approach)
Two completely separate knowledge bases, never connected:
- Production knowledge base: The existing accumulated stack. Notion command center, Claude skills library, client SOPs, BigQuery operations ledger, everything tagged to specific clients and projects. This is the source of truth for the consulting practice. It never touches the public-facing system.
- Clean room knowledge base: Hand-written or heavily-reviewed generalized patterns. Contains zero client-specific information, zero credentials, zero internal strategy, zero personal references. Each entry is a standalone generalized lesson that could have been written by anyone with similar experience. This is what gets exposed via the API.
The transfer between the two is manual or heavily reviewed, never automated. A regex filter is not a clean room. A human reading each entry and rewriting it is.
Minimum Viable Legal Stack
- Separate LLC for the product (shields the consulting practice)
- Terms of Service with explicit liability cap (typically capped at fees paid in last 12 months, or for free service, capped at $0 plus minimal statutory damages)
- Privacy policy covering what gets logged and retained
- Errors and omissions insurance ($1M coverage typical, runs $500-1500/year for a small operation)
- Clear “informational, not professional advice” disclaimers on every API response
- Logged consent that the user understands the service is generative and may produce incorrect output
Adjacent Concepts Worth Tracking
- “Context as a service” as an emerging category — distinct from memory layers. Memory layers store what the user told them. Context services ship with knowledge already loaded.
- The methodology-as-product pattern — Shape Up, Getting Things Done, the 4-Hour Workweek. These are all examples of operational wisdom productized into something that can be sold separate from the consulting practice that generated it.
- Loss leaders as PR for consulting practices — 37signals’ Basecamp, Stripe’s documentation, Vercel’s open source projects. The free or cheap thing is the marketing for the expensive thing.
- The “API for vibes” risk — products that promise “it just works better” without explaining why are hard to differentiate, hard to defend in court, and hard to upsell. The product needs at least one concrete claim that can be measured.
Last updated: April 2026. Knowledge node tags: AI memory layers, productization, second brain, RAG, context engineering, loss leader strategy, clean room architecture, Mem0, Letta, Zep, agency productization, AI tooling business models.