It was late. I had Claude Code open on my laptop and a fresh cup of coffee going cold next to it.
Notion had shipped Workers eight days earlier — their new hosted serverless platform, basically “run real code inside Notion without managing a server.” I’d been meaning to dig in. Last night I finally did.
I want to tell you what that actually looked like. Not a tutorial. Not a polished case study. Just what happened, in order, including the parts that didn’t work.
By midnight I had ten Workers deployed and a live webhook endpoint logging authenticated traffic from the internet into a Notion page. The whole thing took about three hours.
I did not write TypeScript.
Here’s the honest version of how it went.
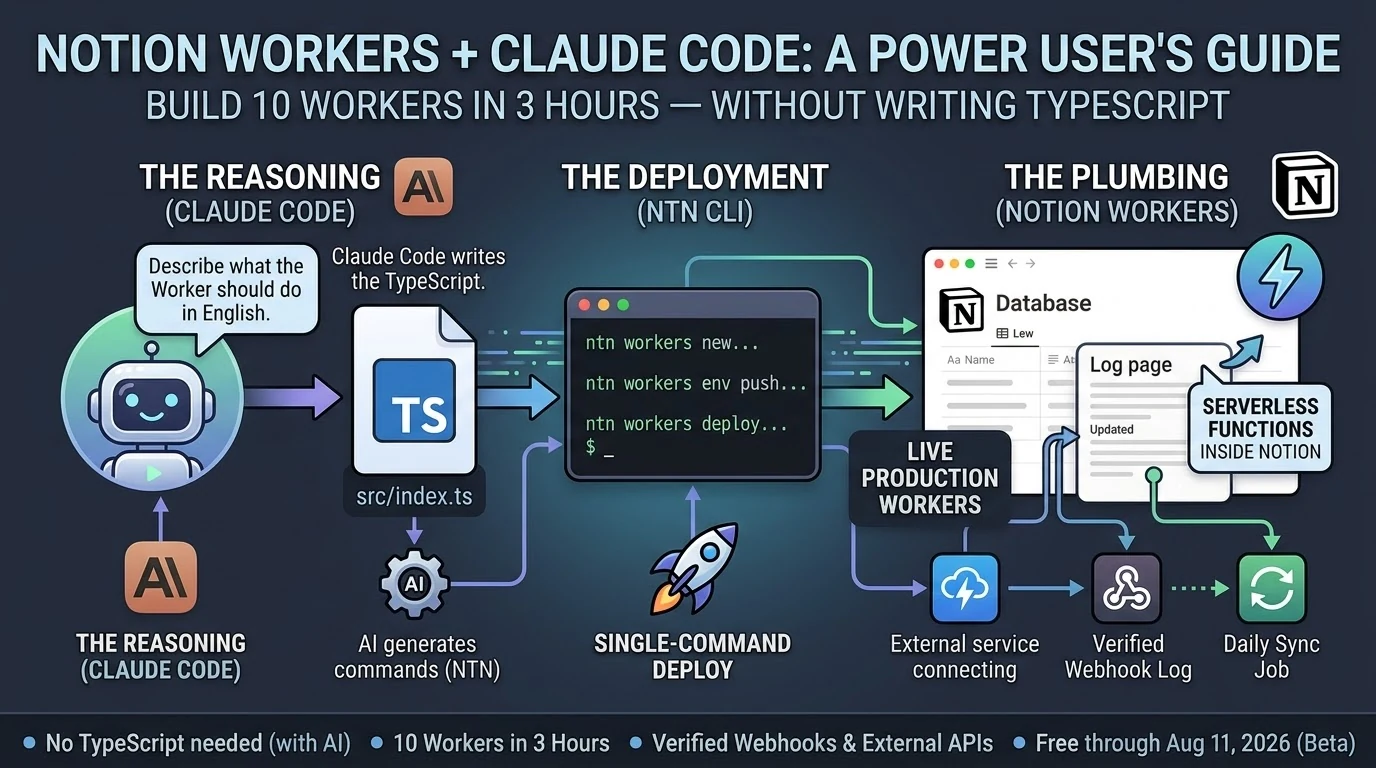
The first Worker took the longest — maybe 35 minutes — because I was figuring out the CLI at the same time as building the thing. The ntn tool is straightforward once you understand it: scaffold, write the code, push your secrets, deploy. Four steps. But the first time through any new tool you’re reading error messages and second-guessing yourself.
Claude Code handled the TypeScript. I described what I wanted — a Worker that receives a POST request, verifies an HMAC signature, and appends a line to a Notion log page. Claude Code wrote it. I ran the commands it told me to run. The Worker deployed.
I tested it. It worked.
The second one took 22 minutes. The third took 15. By Worker five I was moving fast enough that I stopped tracking individual times and just kept going.
Two of them didn’t work on the first try. One had a secret I’d named wrong in the environment — my fault, five minutes to fix. The other had a logic error in how it was handling the Notion API response. Claude Code caught it when I pasted the error back in, rewrote the relevant section, and I redeployed. Eight minutes total for that dead-end.
Neither failure felt like a crisis. That’s the part I want to underline. When something broke, the path forward was obvious: read the error, paste it back to Claude Code, get a fix, redeploy. The loop was tight enough that failure was just a speed bump, not a wall.
At 02:54 in the morning, I sent a test ping to Worker #8.
The webhook logger received it, verified the HMAC signature, and wrote this to a Notion page in real time:
🔔 2026-05-21T02:54:44.452Z [claude-test:test] {"event":"test","message":"Hello from Worker #8 self-test","sender":"claude-code"}I sat there for a second looking at that.
There’s something specific about seeing a system you built actually receive traffic. It’s not the same as a script running on your laptop. This was a deployed endpoint, on Notion’s infrastructure, receiving an authenticated HTTP request from the open internet and writing the result to a database. Automatically. Without me doing anything after the initial deploy.
That’s a different category of thing than what I had before.
I want to be honest about what I am, technically. I’m not a developer. I’ve picked up enough over the years to be dangerous — I can read code, I understand how APIs work, I’ve shipped things — but I’m not someone who sits down and writes TypeScript from scratch.
Last night didn’t require that. What it required was knowing what I wanted, being able to describe it clearly, and being willing to run commands and read errors.
That’s it.
The question I keep hearing from people who run operations like mine — agencies, small teams, people who live in tools like Notion and have always hired out the code work — is whether any of this AI coding stuff is actually for them or if it’s still fundamentally a developer story with a better interface.
Last night felt like an answer. Ten Workers. Three hours. No TypeScript.
If you can describe what you want clearly enough to explain it to another person, you can build this. The friction that used to live between “I know what I want” and “it exists in the world” is genuinely smaller now.
Not gone. Smaller.
You still have to show up. You still have to read the errors. You still have to think through what you’re building before you build it.
But if you’ve been waiting for some invisible threshold of technical credibility before you try — you’re past it. You were probably past it a while ago.
The Notion Workers beta is free through August 11, 2026. The ntn CLI installs in one line. Business or Enterprise plan required to deploy.
📖 Recommended Reading in Claude Code Insider
-
🎯 Pillar Guide:
Claude Code + GitHub in 2026: What Rakuten, TELUS, and a 100K-Star Config File Actually Reveal -
🔗 Next Topic:
The Operator’s Stack