If you run a restoration company doing between $1M and $10M, the software question is no longer “do we need a system?” It’s “which one do we commit to for the next five years, because the switching cost is going to hurt either way.” This is the honest comparison nobody selling you a demo will give you.
The restoration software market in 2026 has consolidated into roughly four serious purpose-built platforms — DASH, Albi, PSA, and Xcelerate — plus a tier of adjacent tools (Encircle, CompanyCam, JobNimbus, ServiceTitan) that solve part of the problem but force you to stitch the rest together. Below is what each one actually is, who it fits, and where it breaks.
The short answer for impatient owners
DASH (CoreLogic / Next Gear): Deepest integration with the insurance ecosystem. The default if TPA volume is more than 30% of your book.
Albi (Albiware): Most customizable. Built by restorers who hated being forced into someone else’s workflow. No native Xactimate integration yet — that is the catch.
PSA (Canam Systems): The value play for larger teams. Flat pricing instead of per-user makes it dramatically cheaper once you cross 10–15 users.
Xcelerate: Best if you want process discipline baked in. Built by a former restoration GM. Strong native integrations, limited customization.
ServiceTitan: Only makes sense above roughly $5M revenue with 20+ technicians and multi-location complexity. Below that, you are buying enterprise overhead.
JobNimbus, CompanyCam, Encircle: Component tools, not full systems. Useful inside a stack, dangerous as the stack.
The four serious platforms, in detail
DASH
DASH is owned by CoreLogic and connects natively to Xactimate, XactAnalysis, Symbility, Encircle, Matterport, and DocuSketch. If you are pulling jobs from Contractor Connection, Code Blue, or any TPA that lives inside the CoreLogic ecosystem, DASH is the path of least resistance. Pricing typically starts around $299/month for core plans and scales into custom enterprise quotes. For TPA-heavy operators it is the default answer.
Where it breaks: Customization is limited. You operate inside DASH’s idea of a restoration workflow, not yours. Owners who pride themselves on “we do it differently” tend to fight the software.
Albi (Albiware)
Albi was built by restoration contractors who got tired of being forced into preset workflows. The platform’s calling card is customization — fields, stages, reports, and metrics bend to your operation rather than the other way around. Open API connects to QuickBooks Online, Zapier, CompanyCam, Encircle, Kahi, and others.
Where it breaks: Per public information, Albi does not have a native Xactimate integration. For a cash-job, retail-heavy shop this is fine. For an insurance-heavy contractor whose entire estimating life lives in Xactimate, it is a real friction point you should walk through with your estimator before signing.
PSA (Canam Systems)
PSA’s pricing model is the differentiator. Where competitors charge per user — which punishes you for growing — PSA quotes flat team-based pricing. Public reporting puts a 10-person team at roughly $350/month against $600–$1,000 for per-user alternatives. The savings compound brutally at 20+ users. Integrations cover Xactware and Matterport, among others.
Where it breaks: The UI is less polished than DASH or Xcelerate. Implementation is more involved. If you have a tech-light operations manager, expect a real ramp.
Xcelerate
Xcelerate was founded by a former restoration general manager, and it shows. The platform bakes operational discipline — profitability tracking, stage gates, team accountability — into the default workflow. Native integrations to Xactimate, XactAnalysis, QuickBooks, Matterport, and Zapier are solid.
Where it breaks: Customization is minimal. The bet Xcelerate is making is that the average restoration company should adopt best practices rather than enshrine its quirks in software. Owners who want the platform to bend to them will be frustrated.
The adjacent tools: useful, but not the whole system
ServiceTitan brings enterprise-grade dispatch, reporting, and marketing attribution, plus restoration-specific modules covering moisture tracking and drying logs. Per-user pricing escalates fast. Unless you are running a multi-location restoration franchise at $5M+ with 20+ technicians, this is too much platform for the problem.
JobNimbus starts around $40/user/month and excels at visual job boards and photo documentation. It lacks restoration-specific guts: no moisture mapping, no equipment tracking, no IICRC S500 compliance prompts. Workable as a starter system under roughly $750K revenue. Above that, you outgrow it.
CompanyCam is a documentation tool, not a CRM. It is excellent at what it does and pairs cleanly with all four major platforms. Do not buy it as your system of record.
Encircle is the field documentation specialist — moisture mapping, photo organization, and report generation are best-in-class. Pricing starts around $149/user/month. Many restoration shops run Encircle alongside DASH or Albi rather than as a standalone.
The decision framework
Forget feature checklists. Three questions decide this for you.
What percentage of your revenue comes from TPA and direct insurance work? If it’s above 30%, DASH gets the first look because the CoreLogic ecosystem is where your jobs live. If it’s below 30% and you are mostly retail, you have real options.
How many users will be in the system 24 months from now? Above 15 users, PSA’s flat pricing pays for itself within a year. Below 10 users, the per-user platforms are competitive on cost.
Are you the kind of owner who wants the software to enforce your process, or one who wants the software to mirror your process? Xcelerate enforces. Albi mirrors. DASH and PSA sit between.
What this costs you if you get it wrong
A restoration company doing $3M with eight users on the wrong platform will typically lose somewhere between 40 and 120 hours of estimator and admin time per month to friction — workarounds, double entry, missing supplements, late invoicing. At a fully loaded $50/hr that is $2,000–$6,000 per month of pure overhead, before you count the supplements that fall through the cracks. Software is not the place to optimize for the cheapest sticker price. It is the place to optimize for the workflow your team will actually use without resentment.
The bottom line
If you are TPA-heavy, start with DASH. If you are retail-heavy with strong process opinions, start with Albi. If you are 15+ users and price-sensitive, force PSA into the demo cycle. If you want the software to make your team better operators by default, look at Xcelerate. Anything else — ServiceTitan, JobNimbus, standalone CompanyCam, standalone Encircle — is either too much platform or too little. Pick one of the four, commit, and stop shopping. The compounding ROI of a fully adopted system always beats the theoretical 12% feature edge of the platform you would have switched to.
Frequently Asked Questions
What is the best restoration company software in 2026?
There is no single best — DASH wins for TPA-heavy operators, Albi for customization-heavy retail shops, PSA for teams above 15 users on flat pricing, and Xcelerate for operators who want process discipline baked in.
Does Albi integrate with Xactimate?
Per publicly available information, Albi does not have a native Xactimate integration as of 2026. It does offer an open API and integrates with QuickBooks, CompanyCam, Encircle, Kahi, Zapier, and others.
How much does restoration CRM software cost?
DASH starts around $299/month for core plans. PSA flat pricing for a 10-person team runs roughly $350/month. Per-user platforms typically run $99–$199 per user per month. Encircle starts around $149/user/month. JobNimbus starts around $40/user/month. All pricing is approximate and subject to vendor quote.
Is ServiceTitan good for restoration companies?
ServiceTitan makes sense for restoration companies above roughly $5M in revenue with 20+ technicians and multi-location complexity. Below that, the cost and implementation burden outweigh the benefit versus a purpose-built restoration platform.
Can I run my restoration company on JobNimbus or CompanyCam alone?
JobNimbus works as a starter system below roughly $750K in revenue but lacks restoration-specific tools like moisture mapping and equipment tracking. CompanyCam is a documentation tool, not a CRM, and should be paired with a full platform.
Most GEO advice in 2026 stops at “add statistics and citations.” That’s true — Princeton’s GEO research paper (Aggarwal et al., 2023) found those two tactics boosted visibility in generative engine responses by up to 40%. But the gap between sites that get cited by ChatGPT, Claude, and Perplexity and sites that don’t isn’t really about more numbers in your paragraphs. It’s about whether the AI system can resolve your brand as a stable entity across the open web before it ever reaches your page.
This is entity binding. It’s the layer underneath every GEO tactic. If you skip it, statistics and FAQs won’t save you. If you do it right, your citation rate compounds.
What “Entity Binding” Actually Means for GEO
When an LLM decides whether to cite a source, it isn’t reading your page in isolation. It’s running a fast resolution step: is this brand a real thing? Does it have consistent attributes across sources? Can I categorize it confidently? The model’s confidence in citing you scales with how unambiguous that resolution is.
Entity binding means making yourself a knowable, consistent entity — not just a domain — across the surfaces AI systems consult: Wikipedia, Wikidata, Crunchbase, LinkedIn, your schema.org markup, industry directories, and the structured data inside Google’s Knowledge Graph. Research synthesized in 2026 by GEO firm Brandlight found the overlap between top Google links and AI-cited sources has dropped from roughly 70% to under 20% — meaning rank no longer guarantees citation. Entity authority does heavier lifting now.
The Four-Surface Entity Binding Stack
Practitioners working on GEO in 2026 should treat entity binding as a stack with four surfaces, in priority order:
On-page Organization schema — the source of truth for your own claims about yourself.
Wikidata / Wikipedia presence — the most heavily weighted external source for knowledge graph construction.
Third-party directories — Crunchbase, LinkedIn company page, industry-specific databases.
Consistent cross-source language — same category, same one-line description, same founding date, same founder names, everywhere.
If even one surface contradicts the others — say, your LinkedIn calls you a “marketing agency” but your schema says “SaaS company” — the LLM’s confidence in citing you drops. Inconsistency is the silent GEO killer.
Step 1: Ship a Clean Organization Schema Block
The foundation is a JSON-LD Organization block on your homepage (and a Person block on your About page if you have a named founder). Here’s a working example you can adapt — drop it inside <script type="application/ld+json"> tags in your <head>:
Two parts do the heavy lifting here for GEO: sameAs (which binds you to external authoritative profiles) and knowsAbout (which gives the LLM topical anchors for when it should consider you a relevant citation).
Step 2: Audit Your Wikidata Footprint
Most independent publishers and B2B brands have no Wikidata entry. That’s a problem because Wikidata is consumed directly by Google’s Knowledge Graph and is one of the most reliable structured sources LLMs pull from during training and retrieval.
The minimum viable Wikidata footprint:
A Wikidata item with at least: instance of, industry, founded by, official website, and headquarters location.
References for every claim — Wikidata rejects unsourced statements, and an unreferenced claim is worse than no claim.
Cross-links to your LinkedIn company ID, Crunchbase ID, and (if applicable) Twitter/X handle.
If you don’t qualify for a full Wikipedia article (most B2B brands don’t), a Wikidata item alone still significantly increases your entity resolution rate inside LLM responses.
Step 3: Normalize Your One-Line Description Across All Surfaces
This is the cheapest, highest-leverage entity binding move and almost nobody does it. Pick exactly one sentence — under 20 words, category-first, no marketing fluff — and use it identically on:
Your homepage meta description
Your Organization schema description field
Your LinkedIn company page About section’s opening line
When five external surfaces and your own schema all say the same category in the same words, the LLM’s resolution confidence is high. When they all say something slightly different, the model hedges — and a hedging model doesn’t cite you.
Step 4: Build Topical Authority Around Bound Entities, Not Just Keywords
Traditional SEO builds topical authority around a keyword cluster. GEO requires you to build it around entities the LLM already recognizes. Practical translation: every pillar article you publish should explicitly name and (ideally) link to:
The canonical entities in your topic (e.g., specific platforms, specific researchers, specific published papers)
The accepted definitions and frameworks from the foundational sources
Your own brand entity, in a way that lets the LLM connect “this topic” to “this publisher”
For a GEO publisher, that means citing the Princeton GEO paper by name, naming Google AI Overviews and Perplexity and ChatGPT search as the specific generative engines, and consistently positioning your own brand as the entity that produces practitioner GEO content. Every article reinforces the entity binding.
How to Measure Entity Binding Is Working
Entity binding is a leading indicator, not a direct ranking signal — so you measure it sideways. The three practical signals to watch:
Brand mentions in AI responses. Manually query ChatGPT, Claude, Perplexity, and Google AI Overviews monthly with 10–20 of your target topical questions. Track whether your brand appears in any cited or recommended source.
Knowledge Graph presence. Search your brand name in Google. A Knowledge Panel appearing on the right side of the SERP is direct evidence that Google has resolved you as a stable entity. No panel after 90 days of entity binding work signals a gap in your Wikidata or sameAs links.
Referral traffic from AI sources in GA4. Filter for sessions where source contains chatgpt, perplexity, claude, or gemini. Sustained growth in this segment is the downstream result of entity binding combined with on-page GEO tactics.
The Common Mistakes
Three failure modes show up repeatedly in 2026:
Shipping schema with placeholder content. A schema block that says “description: Your description here” is worse than no schema. LLMs see it and downgrade trust.
Inconsistent founder names. “William Tygart” on the site, “Will Tygart” on LinkedIn, “W. Tygart” on Crunchbase. Pick one form and use it everywhere — including author bylines.
Treating sameAs as optional. The sameAs array is the single highest-leverage entity binding field in your schema. Empty or partial sameAs is the most common reason small publishers fail to get cited.
Frequently Asked Questions
What is the difference between GEO and traditional SEO?
Traditional SEO optimizes for ranking and clicks on search engine results pages. Generative Engine Optimization (GEO) optimizes for citation, mention, and recommendation inside AI-generated answers from systems like ChatGPT, Claude, Perplexity, and Google AI Overviews. The overlap between top Google links and AI-cited sources has fallen from roughly 70% to under 20% as of 2026, meaning GEO is now a distinct discipline.
What is entity binding in the context of GEO?
Entity binding is the practice of making your brand resolvable as a stable, consistent entity across schema markup, Wikidata, third-party directories, and external profiles so that LLMs can confidently identify and cite you. It is the foundation underneath GEO tactics like statistics addition and source citation.
Do I need a Wikipedia article to be cited by AI systems?
No. A Wikidata item alone is sufficient for most B2B brands and independent publishers. Wikidata is consumed directly by Google’s Knowledge Graph and is one of the most reliable structured sources LLMs use during entity resolution. Wikipedia helps but is not required.
How long does entity binding take to show results in AI citations?
Most practitioners see Knowledge Panel appearance within 30–90 days of completing the four-surface stack. AI citation rate increases lag by an additional 30–60 days because LLM training and retrieval cycles update on slower cadences than search engine indexes.
What schema type should small publishers use?
Use Organization schema on your homepage and Person schema on your About page. If you publish frequently, add Article schema to individual posts and link the author Person back to the Organization. This three-way linkage gives LLMs the cleanest entity graph to resolve.
The Bottom Line
Entity binding is not a one-time setup task. It’s the underlying condition that makes every other GEO tactic work. Before you spend another month adding statistics and FAQ sections, audit your four surfaces, normalize your one-line description, and ship a clean Organization schema with a complete sameAs array. The publishers winning the citation game in 2026 are the ones whose entity resolution is so unambiguous that the LLM never has to hedge.
There is a workflow gap most Claude Code users walk straight into and never quite close. CLAUDE.md tells Claude what should happen. Plan mode lets you see what Claude intends to do. Hooks decide what Claude is physically allowed to do. Pick any one of those in isolation and you get a tool that is impressive in a demo and unreliable in a real repo. Pair plan mode with hooks the right way and Claude Code stops being a chat surface and starts behaving like a constrained junior engineer you can leave alone for an hour.
This is the workflow I have moved every non-trivial repo onto. It is not the simplest setup — that would be raw claude with a CLAUDE.md and trust. It is the setup that survives the moment Claude decides, with great confidence, to delete the wrong file.
The three layers, and why most people only use two
Claude Code as a programmable platform has three durable surfaces for shaping its behavior in 2026:
CLAUDE.md — the markdown memory file Claude reads at the start of every session. Project conventions, glossary, “don’t touch this directory,” coding style.
Plan mode — the read-only review gate, activated with Shift+Tab twice or /plan. No edits, no shell, no git. Claude proposes an implementation plan against the live codebase and waits.
Hooks — deterministic shell scripts that fire on specific tool calls or session events. Pre-commit linting, blocking edits to generated files, refusing pushes to main.
The standard pattern I see in repos is CLAUDE.md plus vibes. Sometimes plan mode for the big tasks. Almost no one is running hooks until they have been burned once. That is the wrong order. Hooks are not advanced — they are the thing that lets plan mode actually mean something.
The reason is empirical and uncomfortable: CLAUDE.md instructions get followed roughly 70% of the time. That is acceptable for “prefer arrow functions” and catastrophic for “don’t push to main.” Plan mode raises the floor on the high-stakes decisions because you see the plan before any tool runs. Hooks raise the ceiling on the boring ones because they execute regardless of Claude’s intent.
What the pairing actually looks like
The mental model: plan mode is for novel work where you need to inspect the strategy. Hooks are for recurring boundaries you do not want to inspect ever again. If you find yourself reviewing the same kind of decision in plan mode twice, that decision belongs in a hook.
A concrete setup from one of my repos:
CLAUDE.md — short. Project glossary, the test command, the “production data is in prod/ and is read-only” rule, the rule that all new files in src/ need a test in tests/. Maybe forty lines. No essay.
Plan mode discipline — anything that touches more than three files, anything that changes a public interface, anything that touches the database schema, I open with /plan. I read the plan. I push back. Then I let it run. For one-file edits, bug fixes I have already scoped, or doc changes, I skip planning. The cost of planning a two-line fix is higher than the cost of undoing it.
Hooks doing the actual enforcement. This is where the work lives. The hooks I run on every active repo:
A PreToolUse hook on Bash that blocks any command matching git push.*main, rm -rf, or any reference to a path under prod/. Returns a non-zero exit and tells Claude what to do instead.
A PreToolUse hook on Edit and Write that refuses any file path matching the generated-code globs from .gitattributes. If the file is autogenerated, Claude is rewriting source-of-truth, not output.
A PostToolUse hook on Edit that runs the linter on just the touched file and surfaces the diagnostics back to Claude. Cheap, fast, closes the loop without waiting for the next test run.
A Stop hook that runs the test suite. Claude does not get to mark the task done if tests are red. This single hook eliminated about 80% of my “it said it was done but” moments.
That last one is the one I would put in every repo before anything else. Without it, Claude verifies its work using its own judgment, which degrades as context fills. With it, each red-to-green cycle is an unambiguous external signal that the work is actually done.
Where this pairing earns its keep
Two scenarios where the plan-mode-plus-hooks combination pays for the setup time:
The unfamiliar-codebase refactor. Claude in plan mode reads the codebase, proposes a refactor across eight files, lists what it will touch and what it will leave alone. You scan the plan, notice it wants to modify a file in a directory that should be read-only, and instead of arguing in chat you add a hook. The hook is now permanent. The next session cannot make the same mistake.
The long-running, multi-step job. You send Claude off to add a feature with twelve subtasks. You are not watching. The Stop hook running tests means Claude either finishes with a green suite or stops and reports. The push-to-main hook means even if Claude decides the merge looks fine, it physically cannot ship it. You get back, read the report, merge. The autonomy is real because the guardrails are real.
What this pattern is not
It is not a replacement for reading Claude’s diffs. Hooks catch categorical mistakes — wrong directory, wrong branch, wrong command — and miss subtle ones, like a refactor that compiles and passes tests but breaks a contract no test covered. Plan mode catches strategic mistakes — wrong approach, wrong scope — and misses tactical ones, like an off-by-one. You still review code. You just stop spending review time on things a script can check.
It is also not a substitute for subagents or skills. Hooks are deterministic enforcement. Subagents are context isolation for parallel work. Skills are reusable procedural knowledge. The Anthropic team’s own framing — start with skills, add hooks when you need deterministic enforcement, add subagents when parallel work or context isolation matters — is correct, and the three layers compose. But the order most practitioners actually need is the inverse of the order they reach for. Most teams reach for subagents first because they sound powerful. Hooks are what makes any of it trustworthy.
The setup that gets you to a usable baseline
If you have one hour, do this in this order:
First, write a forty-line CLAUDE.md. The test command, the build command, the directory rules, the glossary. Do not try to write an essay about your codebase. Claude will read it every session — keep it dense.
Second, add three hooks: a PreToolUseBash hook blocking destructive commands on your protected paths, a PostToolUseEdit hook running the linter on the touched file, and a Stop hook running the test suite. Twenty lines of shell each. None of them require any framework — they are just executables that read JSON from stdin and exit non-zero to block.
Third, develop the habit of /plan for anything you would not be comfortable letting a new contractor commit without review. For everything else, let it run.
That is the baseline. You can layer on subagents, MCP servers, skills, custom slash commands — all of it is useful, none of it is required to ship reliably. The reliability comes from the boring layer: a memory file Claude reads, a plan mode you actually use, and hooks that mean what they say.
The Claude Code documentation will teach you the syntax for any of this in an afternoon. The pattern is the part that took a year of watching it go wrong to settle on.
Sources: Anthropic’s Claude Code documentation, the model list at the Anthropic docs site (verified at runtime), and a year of repos.
A Second Take on The Rise of the Curation Class, published here yesterday. The original named a demographic. This one names the working architecture underneath it — and argues that for solo operators willing to assemble the substrate, the Curation Class is not an emerging future. It is a present tense.
The Thesis from the Source Post
The original piece described a newly emerging demographic — the Curation Class — defined by its rejection of mass-produced goods in favor of personalized, bespoke experiences. Unlike the mass-luxury class that hired professionals to curate taste for them, the Curation Class authors its own taste. It uses interconnected ecosystems to make personal authorship coherent and reproducible across time.
Five technological signatures distinguish them:
They value the interconnected ecosystem over the device. The phone, the ring, the wearable — these are access tokens. The ecosystem is what the tokens unlock.
They want invisible, frictionless interfaces. When the ecosystem works, it disappears. They will pay a premium for the subtraction of friction.
They use AI as an instrument, not a replacement — to make their own decisions legible and reproducible, to check their work against their own internal standards.
They demand a user-owned Second Brain — a persistent personal memory layer that crosses contexts, owned by them, not by a vendor.
They require hyper-personalized verification — relationships and protocols specifically tuned to them, verified, traceable, theirs.
The source frames this as a consumer emergence — luxury tech for the post-luxury class.
That frame is correct as far as it goes.
This is the case that it does not go far enough.
The Second Take
The Curation Class is not a demographic waiting to be served by better consumer products. It is a working operating model. The people the source describes are not waiting for a wearable to ship. Many of them already have the stack. They built it themselves out of components that do not, in any obvious way, look like luxury goods.
The substrate is not titanium and cashmere. It is Notion, Claude, and Google Cloud Platform, wired together with a small number of disciplined patterns.
This is not a hypothetical. It is what Tygart Media runs on. The same five signatures the source identified — ecosystem over device, invisible interface, AI as instrument, user-owned Second Brain, hyper-personalized verification — are present in the production system that publishes this article. They are not aspirational. They have names, IDs, deployment dates, and gate-failure logs.
What follows is the architecture. Not as a brag. As a working diagram of what the Curation Class looks like when you build it instead of buying it.
1. The Two-Plane Architecture — Ecosystem Over Device
The canonical architecture has two planes and a brain.
Notion is the Control Plane — the warehouse and the face. It holds every spec, every database, every Work Order, every Promotion Ledger row, the entire Second Brain. The operator owns it 100%. Notion stores and surfaces. Notion does not think.
Google Cloud Platform is the Compute Plane — the plumbing. Cloud Run executes the workers. Cloud Scheduler triggers them. Workload Identity Federation authenticates them without stored keys. The operation’s technical partner owns it 100%. The compute is inside a VPC the operator owns.
Then there is the brain.
Claude is the brain. Not a plane. Not a leg of the stool. The operator’s instrument. Specifically: Claude Code on the laptop for heavy execution — file ops, deployments, multi-step agentic work, Work Order drafting, reading from and writing to the warehouse — and Claude chat on mobile for orchestration, thinking, captures, on-the-go decisions, and conversational architecture sessions. The brain operates outside the warehouse and dispatches work into both planes.
The handoff between planes is a structured artifact called a Work Order. The operator, working through Claude, decides that a new capability is needed. Claude drafts a Work Order in Notion that specifies what the capability does, what triggers it, what it reports back. The compute-plane operator reads the Work Order, designs the GCP implementation, builds the Cloud Run service, and wires the trigger so the warehouse can fire it directly. The Promotion Ledger logs the new behavior and starts its seven-day clean-day clock.
This is the Curation Class’s first signature made literal. The value is not in any one tool. Notion alone is a planner. GCP alone is a hyperscaler. Claude alone is a chatbot. Wired together with the operator and the compute partner each owning one plane and the brain moving freely between them, they are an ecosystem. The operator does not stare at any one screen. The operator stares at outcomes.
The device, in this frame, is whatever the operator happens to be holding. The laptop runs Claude Code. The phone runs Claude chat. The warehouse runs in a browser tab. The plumbing runs in a region the operator never visits. The ecosystem is the architecture.
A real production note worth surfacing here: this architecture is recent. The operation tested an earlier version that put the brain inside Notion — Notion AI as orchestrator, Notion Workers as the thinking layer. The quality ceiling was too low. Notion AI is excellent at retrieval and at acting on the warehouse from inside it. Its reasoning and orchestration quality lagged the frontier models accessed natively. The doctrine update happened in the last twenty-four hours. The brain moved back outside. Claude Code on laptop and Claude chat on mobile became canonical. This is the kind of decision the Curation Class actually makes — not picking the integrated all-in-one solution because it is convenient, but picking the right tool for each plane and accepting the cost of wiring them together.
2. The Promotion Ledger and the Tier Ladder — AI as Instrument, Not Replacement
This is where the source post stops gesturing and the working system has to commit. The Curation Class wants AI that checks its work against its own internal standards. Fine. What does that look like in production?
It looks like a Promotion Ledger.
Every autonomous behavior in the system — every scheduled worker, every published post, every Slack alert — is logged on a Notion database called the Promotion Ledger. Each behavior has a row. Each row has a Tier and a Status.
The tiers run A through C with a Wings designation above:
Tier A behaviors propose. The system writes a draft, builds a report, surfaces a recommendation. The operator approves via an elevated report — not an atomic per-task confirmation, but a periodic sign-off on a batch. Nothing publishes without approval.
Tier B behaviors prepare. The system stages the work — drafts written, images generated, schemas built, social drafts queued. The operator flies the plane. The system does the ground crew job.
Tier C behaviors run. The system publishes without per-task approval. The operator only sees the work if it fails a gate. Tier C is autonomy.
Wings is the graduated state. A behavior that has run clean at Tier C long enough to be considered structurally trusted.
The ladder is governed by a seven-day clean-day clock. Seven consecutive clean days at a tier — no gate failures, no anomalies, no operator overrides — and the behavior becomes a candidate for promotion. Promotion decisions happen on Sundays. Nothing gets bumped up mid-week.
Failure runs in the opposite direction. A gate failure resets the clean-day clock on that behavior and drops it one tier. The failure is logged with date and reason. The Slack alert points to the row.
This is the structural answer to the Curation Class’s demand for AI that does not replace the operator’s judgment. The system does not improvise trust. Trust is earned by running clean for measurable, public, auditable periods. The operator is not asked to feel confident. The operator is asked to look at the Promotion Ledger.
The Pane of Glass is the live view of the ledger — a single artifact, surfaced in the Cowork workspace, that shows every behavior, its tier, its status, its clean-day count, and the date of its last gate failure if any. It is the dashboard the source post’s Curation Class would recognize. It is also the dashboard a regulator would recognize. Same mechanism. Both audiences served by the same artifact.
The deeper move here is linguistic. The system reports in tiers, not in reassurance. The output of a Tier C behavior is not “Three drafts are ready for your review.” The output is “Three posts published. No anomalies.” The operator does not approve every action. The operator audits the ledger.
This is what AI-as-instrument looks like when you stop saying it and start measuring it.
3. The Context Index and claude_delta — A Second Brain That Stays Legible
The Curation Class wants a persistent memory layer that crosses contexts. Wellness data talks to work schedules. Home environments talk to project files. Disconnected parts of life communicate.
The operational challenge nobody in the consumer pitch ever names is this: any sufficiently large personal knowledge graph hits a context window ceiling. AI models have token limits. A real Second Brain, after a year of accumulation, will not fit in one fetch.
The Tygart Media answer is the Context Index, sharded.
The origin story is unglamorous. The Context Index started as a single Notion page — every important fact about the operation, every credential reference, every architectural decision, every key relationship. At 170 kilobytes of dense Notion markdown, it exceeded the practical fetch ceiling for any model session. Loading it consumed most of the available context before the actual work could begin.
The fix was structural. The 170KB page was sharded into a 6.5KB router and six domain-scoped shard pages. The router holds the index — what each shard contains, which shard to fetch for which task. The shards hold the depth. A session fetches the router first, decides which shards it actually needs, and pulls only those. The router is cheap. The shards are demand-loaded.
The second layer is claude_delta — a JSON metadata block placed at the top of every Notion page in the system. Version 1.0 specifies a small set of fields: page type, related entities, schema references, source post links, status. It is the airport-codes layer of the Second Brain. A model session can scan the delta block and know, in three hundred bytes, whether the page is worth fetching in full.
This is what user-owned memory at scale actually requires. Not the warm assurance that your data is yours. The unglamorous engineering that makes your data fetchable by your own tools at the speeds your work demands. The Curation Class’s Second Brain is not a marketing promise. It is a routing problem solved by router-and-shard architecture and a metadata standard.
The data lives in Notion. The brain that reads it lives in the operator’s own Claude sessions — Code on the laptop, chat on the phone. The compute that runs it lives in the operator’s GCP project. No vendor between the operator and the operator’s own memory.
4. The Fortress Architecture — Hyper-Personalized Verification With Sovereignty Intact
The source post lands on a Concierge Cred Network — the ecosystem verifies the specific barista who knows the exact coffee temperature, the specific protocols tuned to the specific body. Verification is the move. The Curation Class trusts individuals and protocols, not brands.
The security counter-argument is the part the consumer framing glosses. Hyper-personalized verification means a lot of sensitive data flowing through a lot of vendors. Wellness, schedule, location, biometrics, relationships. Every one of those data streams is a vector for surveillance, breach, and lock-in.
The Tygart Media posture is Fortress Architecture. The principle is one sentence: AI connects to WordPress from inside a GCP VPC, not via outbound plugins.
Most AI integrations are sold as plugins. You install something on your WordPress site, the plugin reaches outward to an AI vendor’s API, the vendor sees your content, your traffic patterns, your user data. Convenient. Also a permanent surveillance line into your operation.
The Fortress flips the direction. WordPress runs on a Compute Engine VM inside a VPC the operator owns. The AI tools that act on it — the publishing workers, the schema injectors, the content quality gates — run in the same VPC, on Cloud Run, authenticating with Workload Identity Federation. They reach in over the private network. WordPress is not exposed to the AI vendor. The AI vendor is not even on the path.
The operator’s content, credentials, and customer data stay inside the operator’s perimeter. The Curation Class’s demand for sovereignty is not a feature toggle. It is a network topology choice.
This is the part the consumer narrative cannot land because it would require admitting that most consumer AI is sold by entities whose business model conflicts with the customer’s stated values. The Fortress is the working answer. You do not need to trust the vendor. You need to architect a perimeter in which the vendor does not have standing.
5. The Soda Machine Thesis — The Complete Mental Model
The pieces above are mechanisms. The mental model that holds them together is the Soda Machine Thesis.
The thesis treats a personal Notion workspace not as a productivity app but as an operating company.
Notion is the building. The physical structure inside which the company operates.
Databases are the floors. Master Actions, Content Pipeline, Knowledge Lab, Promotion Ledger — each is a department occupying a floor.
The operator is the Owner. Holds equity, sets strategy, signs off on capital decisions. Does not pour the concrete or run the daily standups.
AI-in-conversation is the Architect. Sits at the table when the building’s structure is being decided. Reviews plans, flags structural issues, drafts elevations. Does not, however, frame the walls.
Custom Agents are the General Contractors. Domain-specific instances of AI with bounded scopes and named responsibilities — the GC for content, the GC for social, the GC for client reporting. They manage the trades and report up.
Workers are the subcontractors. Cloud Run jobs, Cloudflare Workers, scheduled scripts. They do the actual labor on the actual floor. They show up, do the work, file the report, leave.
The Soda Machine name comes from the simplest version of the metaphor. A soda machine is a fully self-contained business — it sells product, collects revenue, restocks itself, calls for service when it breaks. It does not need a human in the loop for the routine. It needs an operator at the top who decided to put it there.
This is the model that makes the Promotion Ledger coherent. The Tier C behaviors are soda machines. The Tier A behaviors are GCs proposing new construction. The operator is not the construction worker. The operator is not even the foreman. The operator is the one who decides which buildings to put up and which floors to add.
The Curation Class signature this resolves is the deepest one — the demand to design one’s own life and have the design hold across years. The Soda Machine Thesis gives the language for what kind of structure the design is. Not a workflow. Not a productivity system. A holding company, with a portfolio, with trades, with audits.
6. The Human Substrate — Why This Particular Ledger
A working system carries the fingerprints of the person who built it. The Promotion Ledger is no exception.
The ledger’s seven-day clean-day rule and three-tier trust architecture are not abstract design choices. They trace back to a childhood sorting mechanism — an only child in a military family, moving every two or three years, developing a way to decide what to keep, what to demote to storage, and what to throw out. The decision was always tiered. Always conditional on a clock. Always documented, even if only to himself, because the next move was always coming and the calculus had to survive the move.
The Promotion Ledger is that calculus made operational. Behaviors graduate the way belongings did. Behaviors fail the way belongings did when the next move proved them dead weight. The seven-day clock is the operational version of “if I haven’t touched this since the last move, it does not move with me.”
This matters because the Curation Class signature the source post identifies — the demand for hyper-personalized verification, for relationships and protocols specifically tuned to the operator — only holds if the operator’s tools carry the operator’s actual cognitive fingerprint. A Promotion Ledger written by someone else, even a perfect one, would not be this one. The childhood-sorting origin is what makes it legible to its operator. It also is what makes it defensible — when a gate fails and the system demotes a behavior, the operator does not argue with it. The mechanism is older than the system.
This is the human substrate the consumer pitch cannot reach. The bespoke AR ring is bespoke in finish. The Promotion Ledger is bespoke in mechanism. One is a luxury good. The other is an operating system.
The Curation Class Is Already Here
The source post described a class waiting for an ecosystem to ship. The honest read is that the ecosystem is shippable today, from components most operators already have access to, if they are willing to do the work of wiring them together with discipline.
Notion accounts exist. Claude subscriptions exist. GCP free tiers are generous enough to run a real operation on. The two-plane architecture with Claude as the brain is a deployment pattern, not a luxury product. The Promotion Ledger is a Notion database with a Tier column and a Status column and a clean-day counter — the schema is not the hard part. The hard part is the operator’s willingness to publish on Tier C without manual review, to let the ledger be the source of truth, to read “three posts published, no anomalies” as the success state instead of asking for the drafts.
That willingness is what the Curation Class actually demands of its members. Not money. Not titanium. The discipline to design a system that runs without you, and then to trust the audit trail when it does.
The consumer version of the Curation Class will eventually ship. There will be expensive rings and curated concierge networks and verified protocols, and the people who can afford them will own them, and the people who sell them will collect the margin.
The operator version is already running.
It looks like a Notion workspace with a Promotion Ledger pinned to the top, a GCP project running quietly inside a VPC nobody else has standing in, Claude Code open on a laptop and Claude chat on a phone, and a person on the other end of the system who does not stare at any one screen because the screens are not the point.
This is what I’m building for myself, and what I’m building for the people I work with. It’s a long essay because the shift it describes is large and the through-line matters. The ten images below aren’t decoration — they’re the spine. Each one is a moment in a life that doesn’t fully exist yet but is closer than most people realize.
I want to start where the technology starts, which is not in a factory.
The man in the image above is finishing a wearable by hand. It’s an AR ring — leather and brushed aluminum, the band sized to his client’s wrist, the materials chosen because his client cares about how the thing feels at 6 AM on the day she has to present to a board. Behind him are leather rolls and fabric swatches that wouldn’t look out of place in a coachbuilder’s atelier. To his right are the kind of objects you’d find in a hardware prototyping lab — chassis teardowns, a development tablet, AR glasses on a stand. The corkboard above the bench has automotive interior sketches and material studies pinned next to each other.
What that workshop is, in operational terms, is a luxury goods atelier and a hardware lab collapsed into one room. The collapse is the thing. The line between “this is bespoke craft” and “this is consumer electronics” has been melting for a decade, and the workshop above is what it looks like once that line is gone.
I’m building for the people who will live on the right side of that collapse. The people who don’t want a phone — they want an instrument that fits the way they think. The people who have stopped trusting mass-produced anything and started looking for the small workshop, the verified maker, the device tuned to them specifically. That’s the Curation Class. They’ve existed in clothing for a hundred years and in cars for sixty. They’re now showing up in technology, and the technology is the part of the story I have to build.
This essay is about what their daily life looks like when the ecosystem actually works. Then it’s about why I think this is where things go from here, and what I’m doing about it.
Introduction to the instrument
Meet the user. She’s the one who commissioned the work in the hero image. She’s an architect — the corkboard behind her is a hint, the mood board with fashion sketches and house renderings tells you something about her aesthetic taste. The coffee cup has a small leather wrap and a logo I won’t try to read; the flower in the vase is past its bloom but she hasn’t replaced it yet because she likes it that way.
She’s just opened the ecosystem the artisan was finishing. The hologram floating above the ring spells out what she’s getting: “Vibe Curation, Concierge Cred Network, Curated Intelligence.” The version number is v1.4, which tells you the device has been iterated. This isn’t a Kickstarter prototype. This is a maintained system that updates the way her car updates and her phone updates, except it updates to fit her specifically rather than to fit the median user.
The phrase “Personalized Ecosystem” deserves to be said carefully because it gets thrown around by everyone selling anything. What’s on her desk is different. It’s not a feature flag set to her preferences. It’s not a recommendation algorithm tuned to her purchase history. It’s an ecosystem in the literal sense — an interconnected set of devices, services, vendors, and contexts that have been wired together around her cognition, her body, her schedule, her taste, and the people she trusts. The wearable is the access token. The ecosystem is everything the token unlocks.
The reason this matters is not that the technology is impressive. It’s that the unit of value is changing. For a generation, the value was in the device. For the next generation, the value is in the connections between the devices and the person who wears them. You don’t buy the ring. You buy your way into the ecosystem that the ring represents. The ring is just the part you can touch.
This is what I’m building toward. Not the device. The connections.
The day starts with a small ritual
The first time the ecosystem touches her day, it’s a coffee. She’s at a café — bright, marble-countered, the kind of place that does third-wave coffee and serves it in a small ceramic cup. The barista is named Maria. The hologram above her ring is showing the order before Maria has had to ask: oat latte, 120°F (which is a specific temperature most people don’t know to ask for), Ethiopian Yirgacheffe roast.
The detail that matters is the parenthetical: “Maria (verified).”
This is the Concierge Cred Network. Maria isn’t just a barista. She’s been verified by the ecosystem — pulled up by name because she’s the one who makes the coffee the way the subject likes it. If Maria’s not working today, the ecosystem might suggest a different café entirely rather than route the order to a barista the system doesn’t trust to nail the temperature. The vendor relationship has become specific to the human, not the brand.
I want to name something about this image that the casual viewer might miss. The subject is barely looking at the ring. Her gaze is on Maria. The interaction is human; the technology is in the background doing the work that makes the interaction friction-free. When the ecosystem works, it disappears. It doesn’t ask her to type her order, doesn’t ask her to dig out her phone, doesn’t ask her to remember which roast she likes. It does that work upstream. What she’s left with is a moment of eye contact and a coffee that’s right.
This is, in my experience, the part most technology gets wrong. The goal isn’t to put more interface in front of people. The goal is to remove the interface from places it doesn’t belong. The Curation Class is willing to pay a premium for that subtraction.
The home she designed for herself
Now she’s home. The wall she’s touching is travertine — real stone, the kind with porosity you can feel under your fingertips. The hologram tells you the room is in a “Curated Sanctuary” mode and lists the materials: travertine and a cashmere blend. The room is calm. The light is afternoon. The chair is leather and looks like it’s been broken in for years.
The detail I want to pull forward is the curator field on the hologram: “User_24A. Verified.”
She is the curator. The “Verified” tag isn’t a brand verification. It’s her own. The space was designed by her, for her, and the ecosystem is tracking that fact. The wall, the light temperature, the fragrance the room is currently running, the sound dampening, the chair — all of it is a vibe she composed and the ecosystem is just executing.
This is where the Curation Class diverges most sharply from the mass-luxury class that came before it. The old luxury class hired Robert Mion or Kelly Wearstler to curate for them. They bought the taste of someone whose taste was for sale. The new class makes the curation themselves and uses the ecosystem to remember the choices and reproduce them. The taste isn’t borrowed. It’s authored. The ecosystem is what makes authored taste tractable at the level of a daily-running home.
I’ll be honest about why this matters to me operationally. When I think about what I’m building for my best clients — the ones who are paying for something more than a website or a content pipeline — I’m not building campaigns. I’m building the systems that let them author their own taste and reproduce it at scale. The Notion structure is part of that. The content stack is part of that. The way we wire models and routing and observability is part of that. None of it is technology for its own sake. All of it is the infrastructure of authored taste.
The room above is what that looks like when it’s done.
The work she actually does
The studio above is hers. The building is hers too — she’s an architect, and “The Veda Residences” is the project she’s leading. The hologram shows iteration v9.2, which means this design has been worked through. The physical model on the leather pad is the build she’s referring to when the holographic version isn’t enough.
A few things to notice. The drafting table has a real architect’s set square on it. The materials board has fabric and stone swatches that look like they were pulled from suppliers she trusts. The two colleagues in the back are visible through a glass partition; the studio isn’t a solo operation. It’s a small firm.
What the ecosystem gives her here isn’t draft generation. It’s not “AI did the design.” The design is hers, plus her team’s. The ecosystem gives her something subtler — the ability to iterate v9.2 against her own internal coherence rules, her own taste profile, her firm’s body of work, the structural and material verifications she requires. She is still making every decision. The ecosystem is making every decision legible and reproducible.
This is the part I think most people get wrong about where AI is going. They think it’s going to do the work. It’s not. It’s going to make the work expressible. The architect above doesn’t need an AI to design her building. She needs an instrument that lets her ask “would this material be coherent with the rest of my catalog?” and get an answer with citations. She needs the ecosystem to be the silent third party that holds her own standards more reliably than she can hold them in her head across a four-month project.
The building she’s designing in this image, by the way, is the one she’ll be standing inside in the last image of this essay. Hold that. We’ll come back to it.
Recovery, the part the ecosystem treats as work
After the work, the recovery. The image above is what wellness looks like when it stops being a separate vertical and becomes a function of the same ecosystem that runs the rest of the day.
The hologram says “Vibe State Recovery (post-design cycle).” That phrase is doing real work. The ecosystem knows she just spent eight hours on iteration v9.2 of the building project. It knows what that does to her body — the cortisol curve, the shoulder tension, the eye strain. It’s prescribing a recovery protocol that’s specific to what she just did. Not a generic massage. Not a generic meditation. A recovery state tuned to a design cycle.
“Second Brain (User_24A): Verified Biometrics” is the connective tissue here. The wellness system isn’t reading her body from scratch. It’s reading her body in the context of everything else the ecosystem knows about her — her schedule, her work, her sleep history, her stress baseline, her medication if any, her preferences for what kinds of intervention she’ll accept. The Second Brain in this image isn’t a metaphor. It’s literally the persistent memory layer that lets every part of the ecosystem behave intelligently with respect to every other part.
If I had to name what I think the single biggest unlock of the next ten years will be, it would be this: persistent personal memory that crosses contexts. Right now your fitness app doesn’t know what your therapist said. Your calendar doesn’t know what your sleep tracker measured. Your travel booking doesn’t know your spouse’s allergy profile. Each of these systems is islanded. The Curation Class will be the first cohort to live in a world where those islands are connected, and the connection will be the persistent personal Second Brain that they own — not a vendor’s database. Theirs.
This is, again, why I do what I do. Not because I want to sell people on “AI wellness.” Because the architectural pattern of a persistent personal Second Brain, owned by the human, is the foundation everything else rides on.
A deeper intervention
The session continues. She’s now holding a more specific tool — a neural stim device that’s been issued to her, the kind of thing that has to be verified for her specifically because applying it wrong would do real damage. The hologram says “Neural Pathway Targeted: Verified.” The ecosystem isn’t just letting her use the device. It’s verifying that the protocol is appropriate for her at this moment.
The phrase “Vedic Regeneration” is doing some cultural work here. I’m not going to oversell it — different people will read different things into it. What I’ll say operationally is that the Curation Class tends to be polyglot about where its wellness traditions come from. They’ll combine cold plunges, somatic therapy, Ayurvedic principles, and neural-feedback hardware in the same week without feeling the contradictions. The ecosystem is what makes that polyglot stance tractable — it can hold the protocols from five different traditions and apply the one that fits the moment.
The reason a verification layer matters is harder. We’re entering an era where people will be doing more sophisticated interventions on their own nervous systems than ever before. Some of those interventions will be safe. Some won’t. Some will work for one person and harm another. The ecosystem above is doing what regulators won’t be able to do for another fifteen years: assuring that a specific intervention is appropriate for a specific person on a specific day. The verification isn’t bureaucratic. It’s the thing that lets her safely run the protocol at all.
I’ll name the discomfort here. There’s a version of this that ends badly — concentration of biometric data, vendor lock-in, dependence on a system that someone else can shut down. That risk is real. The mitigation isn’t to refuse the technology. The mitigation is to own the Second Brain rather than rent it. Which is part of why I’m building the way I’m building. The architecture matters. The architecture is the politics.
The commute as part of the system
She’s in the car now. It’s autonomous — the road is moving but her attention is on the floating dashboard. The destination on the hologram is her own design studio at 11 Rivoli. ETA fourteen minutes.
The phrase that earns its keep is “Flow State Curation.” The car isn’t just transporting her body. The car is preparing her cognition for what’s about to happen at the studio. Audio profile tuned. Cabin temperature optimized. Lighting on a curve that brings her up into focus rather than letting her crash at the end of the recovery session. The fourteen minutes between wellness and work aren’t dead minutes. They’re a transition that the ecosystem is actively shaping.
When I look at this image I think about how much of contemporary life is wasted in transitions. The Curation Class won’t tolerate it. Their time is their most expensive asset, and they’re willing to pay to have transitions be productive rather than evaporated. The autonomous car is part of that. So is the ring. So is the wellness suite. So is the studio. None of them in isolation is interesting. Stitched together they are an enormous economic shift.
The other thing worth naming: the car is bespoke. “Smart cashmere & polished aluminum, verified.” This is not a leased Tesla. It’s a vehicle whose interior materials have been chosen for her, verified by the maker, and integrated into the ecosystem in a way that lets the car participate in the flow state curation rather than fight it. The market for that kind of vehicle barely exists today. It will exist in ten years, and it will be larger than people think.
Collaboration at scale
The studio meeting. Four colleagues, a marble table, a wall of glass onto the city. She’s standing because she’s leading.
The hologram says “Group Alignment 88%.” That’s the part I want to pull forward. The ecosystem isn’t just running her individually — it’s running a measurement of how aligned her team is on the current iteration of the project. Eighty-eight percent is high. Twelve percent is the gap she has to close in the room.
This is where the Curation Class moves from being a personal lifestyle to being an operational advantage. A team that can see its own alignment in real time, that can identify the twelve percent of disagreement and address it directly rather than letting it metastasize through three more meetings — that team will outperform a team that can’t. The ecosystem is doing the work of measurement that used to require an executive coach in the room. Now it’s just there, on the table, visible to everyone.
I want to be careful here. There’s a version of this where the alignment metric becomes a cudgel, where dissent gets flattened by the pressure to push the number up. That’s a failure mode and the ecosystem above can absolutely become it if the culture around it is wrong. The fix isn’t to refuse the measurement. The fix is to make the measurement legible enough that disagreement is preserved as signal rather than erased as noise. The ecosystem can do that. Whether the team uses it that way is a cultural question, not a technological one.
The technology, by itself, is neutral. The culture decides whether it’s surveillance or instrumentation. I’m building for the latter.
The arc closes
This is the image that earns the whole essay.
She’s standing inside the building. The Veda Residences — the project that was iteration v9.2 in the studio scene — is now built. The curved concrete, the fluted glass, the composite timber that the hologram in that earlier scene specified, all of it has gone from model to reality. She designed the room she is now living in. The hologram above her is reporting that the sanctuary is “realized” and that the alignment is at 100%, which is the team-level analog of the personal sanctuary she was tuning at home.
She designed her own world into existence. The ecosystem made the through-line tractable across nine months of design iterations, two construction phases, fifteen vendor relationships, three biometric recovery cycles, a hundred small daily curations, and the original choice — three years earlier — to commission a hand-finished AR ring from a maker who works with leather and aluminum on a single bench.
The Curation Class is not, fundamentally, a class that consumes better products. It’s a class that authors its own life and uses an ecosystem to make the authorship coherent across time. The wearable, the home, the studio, the wellness suite, the car, the team, the building — these are all expressions of one continuous act of authorship. The technology is the substrate. The taste is the act. The realization is the proof.
Why I’m building for this
I started this essay by saying it’s about what I’m building for myself and my clients. I want to close on that more directly.
I am not building generic AI tools. I am not building “content automation.” I am building the operational substrate that lets a person — a founder, an operator, an artist, an architect — author their own coherent system across time and have the system reliably express the authorship. That’s the Notion architecture. That’s the model routing layer. That’s the content pipeline. That’s the persistent memory. None of it is interesting in isolation. All of it is interesting because of what it adds up to.
The person I am building for is the architect above. She doesn’t know me. She might not exist yet. But the infrastructure that makes her life tractable is the infrastructure I am wiring this week, this month, this year. Every client I take on is a step toward making the substrate real. Every article I publish is a way of describing the future I’m trying to bring forward. Every system I document is a piece of the operating manual for the Curation Class.
I think this is the work. I think it’s where the next ten years are. I think the people who get this right will look back at the current era — when AI was being used to mass-produce the same five blog posts and the same five product descriptions — the way the Bauhaus generation looked back at Victorian ornament. They will see the gap between what was being built and what could have been built, and they will name it.
I’m trying to be on the right side of that gap.
The image above — the woman standing inside the building she designed, with a glass of water, watching the city she optimized — is what I’m working toward. Not for her specifically. For the version of that life that becomes available to anyone who decides to author it and has the infrastructure to do so. That’s the Curation Class. That’s the brief I’m operating under. That’s the future I’m building.
It’s already starting. The man in the first image is finishing the ring by hand. The system is being built. The class is forming. The rest is execution.
Most teams generate images for multi-piece content one API call at a time. The result is a set that shares general aesthetics but loses visual DNA at the seams. This article makes the case for generating cohesive image sets in one conversation context instead — and shows what each method actually produces.
Sequential vs parallel image generation: Sequential generation creates multiple images inside one conversation with an image-capable model, so each image inherits visual DNA — palette, perspective, geometric language, compositional rhythm — from the prior images in the same context window. Parallel generation creates each image in a separate API call, with no shared context, producing sets that share keywords but not feel. Use sequential for cohesive image sets where the visual identity matters; use parallel for high-volume independent images.
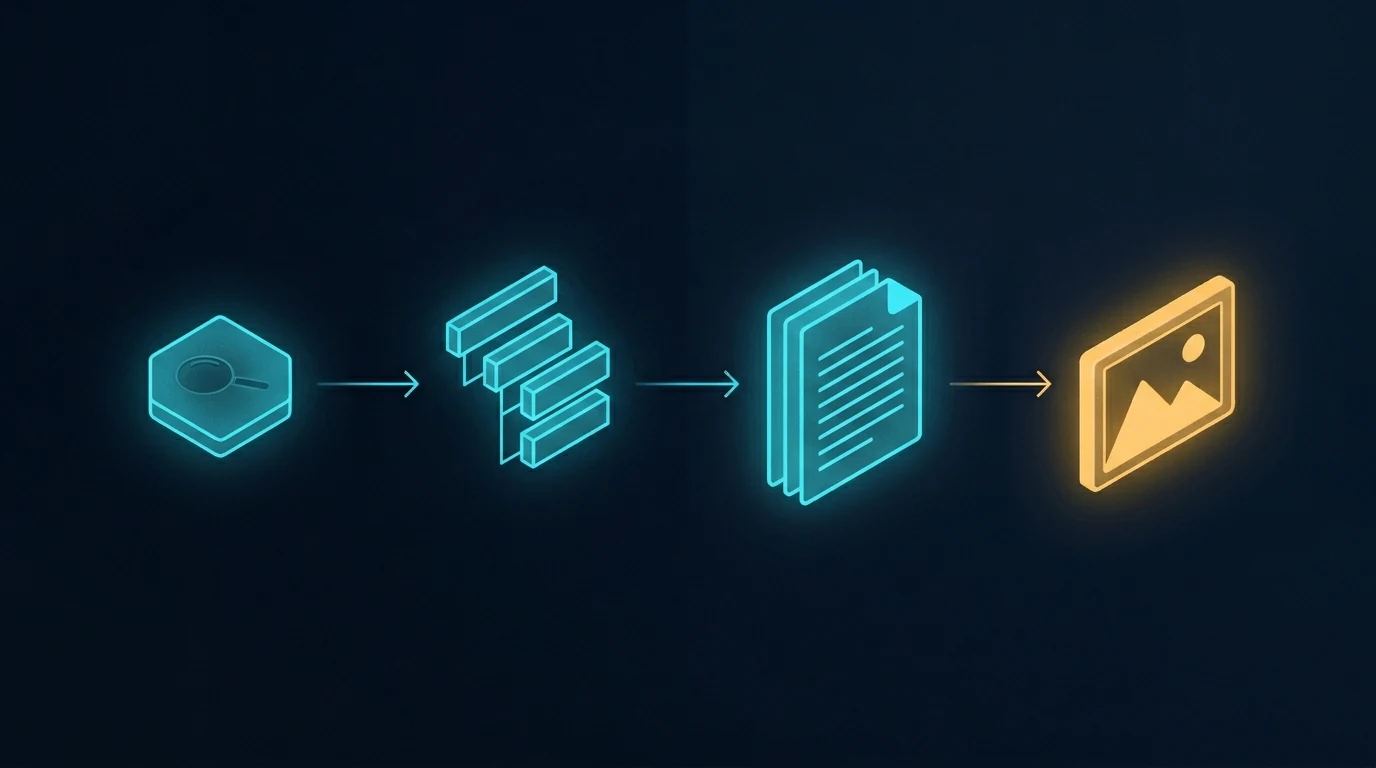
The image above is a simple visual contrast — one workflow on the left, a different workflow on the right, with an arrow pointing from one to the other. It’s also the kind of image you can only get reliably when you generate it as part of a series, in conversation with a model that already knows what visual language you’re working in. Generated cold, in isolation, the result drifts. Generated in context, alongside five other images sharing the same DNA, the result locks in.
This article is about why that happens, what it means for content production, and when to use which method.
What “in one context” actually means
When you generate an image with a typical API call, the model receives your prompt with no memory of any prior image. Each call is a cold start. The model interprets your style instructions from scratch every time. If you ask for “isometric perspective, dark navy background, cyan and amber accents” five times in a row, you’ll get five images that broadly match those words — but they won’t actually share visual DNA. They’ll share keywords.
When you generate in a single conversation with an image-capable model like Gemini, every image you’ve already made stays in the context window. The model sees what it just generated. The next image inherits the palette, the geometric vocabulary, the compositional rhythm, the lighting treatment, the specific aesthetic flavor of the prior images — not because you re-described those things, but because the model is continuing a project, not starting a new one.
That distinction sounds small. The output difference is large.
The conventional pipeline that produces parallel generation
The image above shows the standard content pipeline. Research the topic, outline the structure, write the document, generate an image to go with it. When the article needs more than one image, the last step gets parallelized — multiple API calls fired in sequence or in parallel, each one a separate request, each one independent of the others.
This is how every CMS template works, how every batch image pipeline is built, and how most automated content systems run. It’s efficient. It’s fast. It scales to hundreds of images across hundreds of unrelated posts. And it’s exactly the right tool for that volume work.
It is not the right tool when the images are meant to belong to each other.
What parallel generation actually looks like
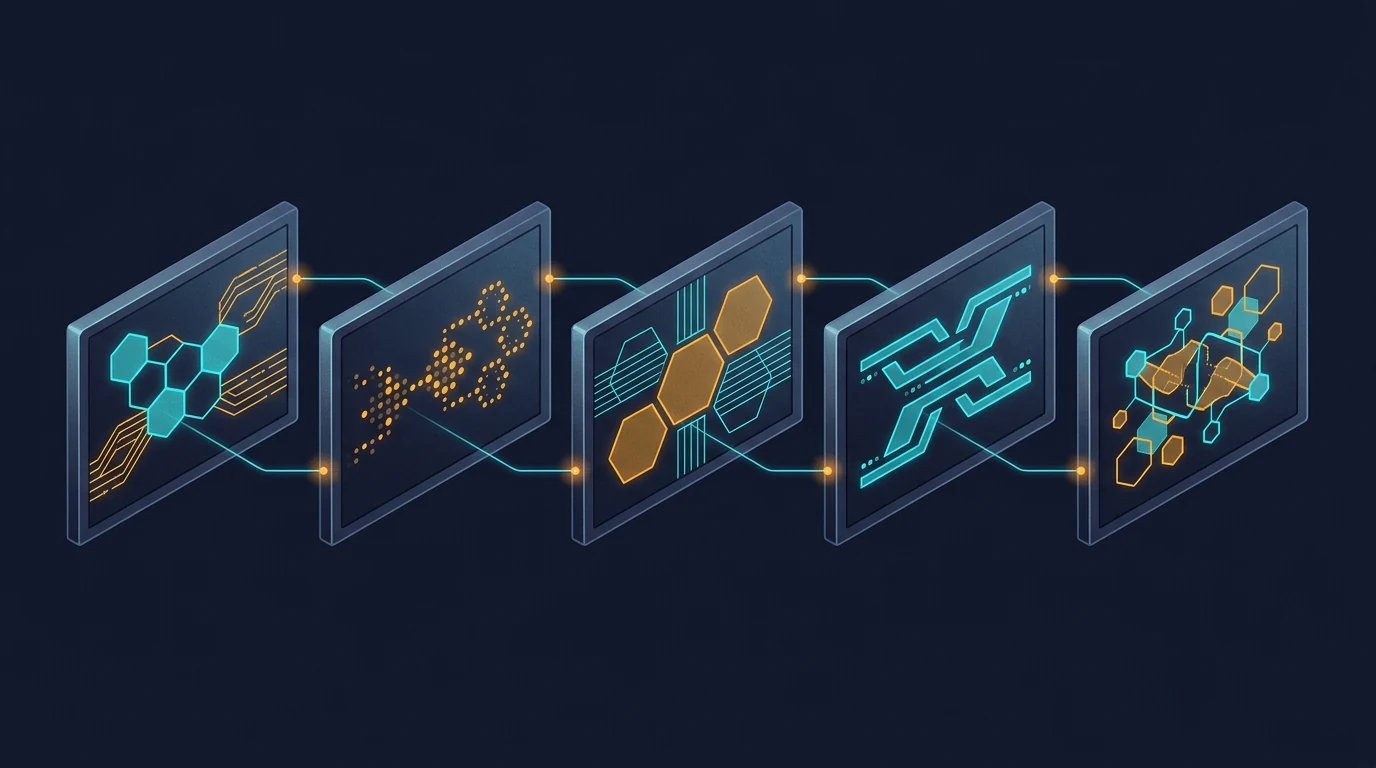
The image above shows the contrast plainly. Six frames, each containing a different abstract composition. They share a general aesthetic because the prompts asked for it — there’s a recognizable common style budget. But look at the actual visual content: one frame leans cool cyan, another leans warm amber, one uses hexagonal circuit patterns, another uses soft organic blobs, another uses sharp angular fragments. The compositional logic drifts. The palette drifts. There are no threads between them because there’s nothing connecting them in the model’s understanding.
This is what parallel image generation produces, even with carefully written prompts. Each call follows instructions in isolation. Each call invents its own interpretation of “dark navy with cyan and amber accents.” The instructions don’t lie — every frame is technically dark navy with cyan and amber — but the feel drifts because there’s nothing keeping it locked.
A reader scrolling past doesn’t consciously notice. They just feel, vaguely, that the images don’t quite belong together. That vague feel is the cost.
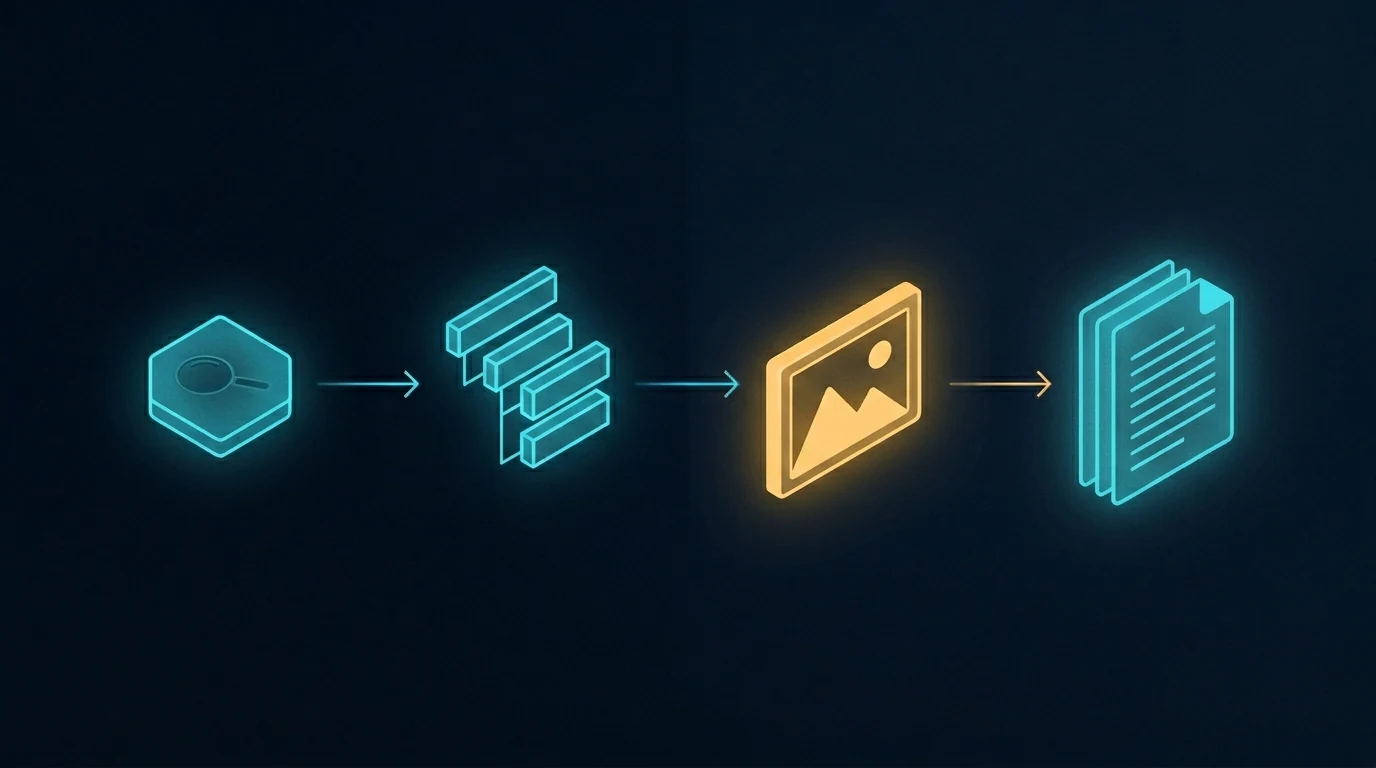
What sequential generation produces
The image above shows the difference. Five frames, all generated in a single conversation. The visual continuity is immediately obvious — every frame uses the same palette, the same geometric vocabulary (hexagons, circuit traces, glowing nodes), the same compositional rhythm, the same slightly-elevated isometric perspective. The frames are different from each other in content — they’re not duplicates — but they belong to the same designed system.
The connecting threads in the image are the metaphor. Visual DNA flows from one frame to the next. The model doesn’t reinvent the aesthetic on frame two; it continues it. By frame five, the system has cohered so tightly that the model is generating within a style rather than generating to a style.
This is what context does. Every image you generate in that conversation is one more anchor point. The model has more to reference and less to invent. The fifth image is easier to make than the first, because the context has already done most of the work of specifying what the image should be.
The seam test
Here’s the practical diagnostic for whether your image set needs sequential generation: imagine the images displayed next to each other, maybe in a carousel or a grid, maybe as featured images for a series of related articles. Imagine a reader seeing them at a glance.
Do the images need to feel like one project? Like five views of the same world?
If yes, sequential generation is the right method. If the images can stand alone without referencing each other — a featured image on a daily blog post, a stock illustration for a generic article — parallel generation is fine and probably better. Speed and throughput matter more than coherence when nothing depends on coherence.
The volume tier and the premium tier of image production are doing different jobs. Treating them like one tier and reaching for parallel generation by default is how most teams end up with image sets that almost work.
How to actually do sequential generation
The method is mechanical and worth spelling out:
Open one conversation with an image-capable model that supports conversation context. Gemini works well for this; other models with image generation and persistent context can work too. Paste your style guardrails as the first message — palette, perspective, aesthetic, what you don’t want. Then send your image prompts one at a time, in the same conversation, in the order you want the visual DNA to flow.
Don’t start a new session between images. Don’t summarize prior images in the next prompt. Trust the context window to do the carry-forward.
If an image isn’t quite right, ask for a revision in the same conversation rather than starting over. The model will adjust within the established style instead of regenerating fresh.
When you have all the images you need, the set is done. The cohesion you couldn’t have gotten from six separate API calls is now baked into the image files themselves.
A related workflow worth naming
The image above shows a different rearrangement of the same pipeline — one where the image step jumps forward, ahead of the writing. The article gets written to fit the images, not the other way around. That’s a different topic with its own trade-offs, and we’re covering it in a forthcoming companion piece. For now, the relevant point is that whichever order you use, sequential generation is what makes coordinated multi-image content tractable. Without it, the activation energy of coordinating images is high enough that most teams default to one-off illustrations.
The reverse failure mode
The opposite mistake is also worth naming. Some teams, having discovered sequential generation, try to use it for everything. This wastes effort. A single featured image for a daily blog post doesn’t need to share visual DNA with any other image — it stands alone. Running it through a long conversation is overhead for no benefit.
The split is simple. If the images belong together, generate them together. If they stand alone, generate them alone.
When to use each method
Use sequential generation in one conversation context for:
Pillar plus cluster article sets where the visual identity matters
Multi-image articles where consistency across images is part of the message
Flagship content where readers will perceive the image set as designed
Brand-defining visual systems
Anything where seeing two images side by side and noticing they belong together is part of the value
Use parallel generation across separate calls for:
Single featured images on unrelated daily posts
Site-wide batch fills where volume dominates
Stock-style illustrations for routine content
Background image work where nobody is looking at it twice
Anything time-sensitive enough that the activation energy of opening a conversation isn’t worth it
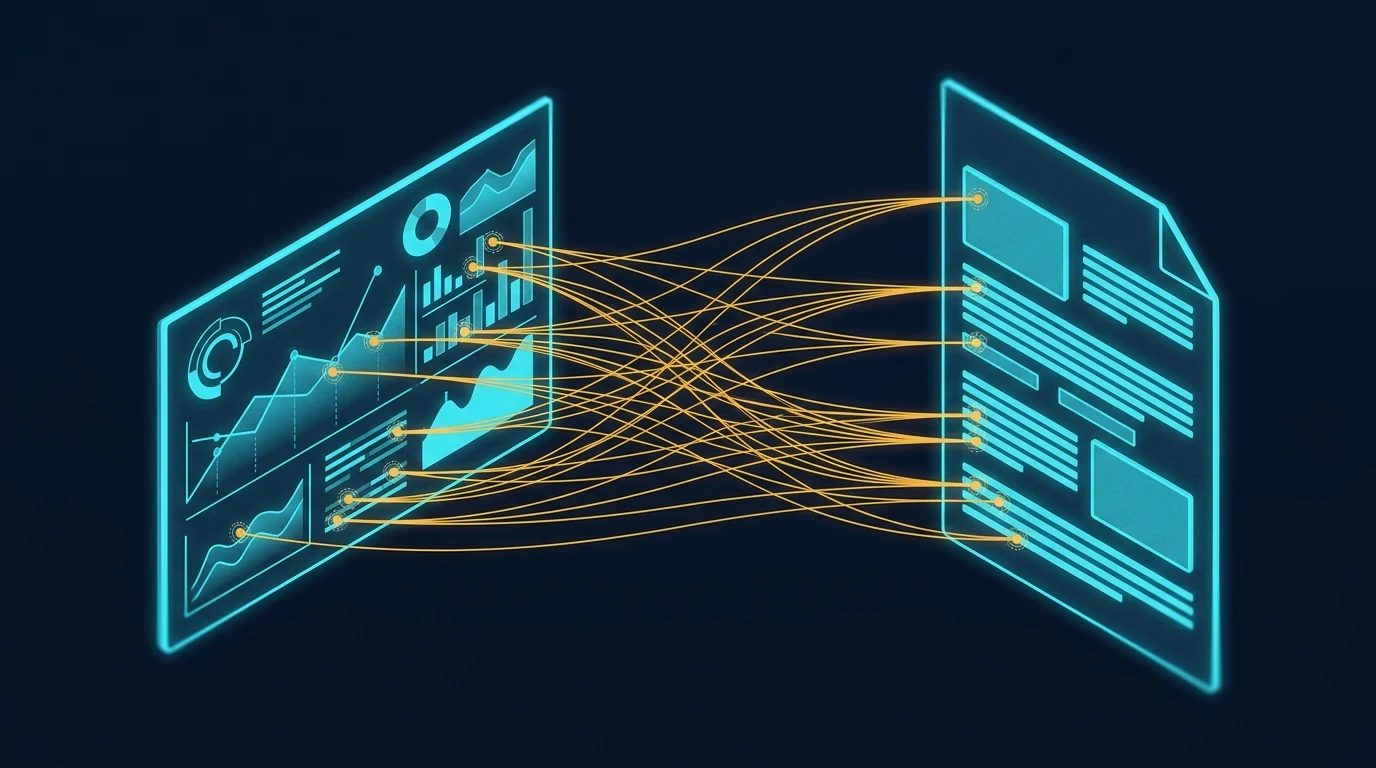
The locked-together effect
The image above shows what coherent visual sets enable in the actual reading experience. When the images in an article share visual DNA, a reader can reference back and forth between them — visual element here, paragraph there — without the cognitive friction of feeling like the images are coming from different worlds. Specific points in one image connect to specific points in another, or to specific points in the text, and the reader’s eye treats them as a system.
That’s what cohesion is worth. Not aesthetic prettiness in the abstract, but the reader’s ability to navigate the content as a unified whole instead of as a sequence of disconnected pieces.
Parallel generation can’t produce this effect reliably. Sequential generation can. The method is the difference.
The premise
The core insight is small enough to fit in a sentence: generate cohesive image sets in one conversation, generate independent images in parallel calls, and don’t conflate the two cases. Everything else in this article is unpacking that one observation.
The teams that get this right produce visual systems that look designed. The teams that get this wrong produce sets that look almost-designed — close enough that nobody complains, far enough that the work doesn’t quite land. The difference between those two outcomes is which workflow you use, and the workflow choice is essentially free once you know to make it.
This very article is a small proof of concept. The six images above were generated in a single Gemini conversation, in sequence. The visual DNA flows across all of them. None of that would have survived parallel generation. The choice was free; the result is visible.
Frequently asked questions
What is the difference between sequential and parallel image generation?
Sequential image generation creates multiple images inside a single conversation with an image-capable model, so each new image inherits visual DNA from the prior images in the same context window — palette, perspective, geometric language, and compositional rhythm carry forward automatically. Parallel image generation creates each image in a separate API call with no shared context, so each call is a cold start that follows style keywords but cannot inherit feel.
Why does conversation context matter for image generation?
When images are generated in one conversation, the model can see the prior images it generated and use them as anchors for the next image. This means visual specifications you set once are carried forward without you having to re-state them. The result is dramatically tighter cohesion than parallel API calls can produce, even when both methods use identical prompts.
When should I use sequential image generation instead of parallel calls?
Use sequential generation when the image set is part of the value proposition — pillar and cluster article sets, multi-image flagship articles, brand-defining visual systems, anything where readers will perceive the images as belonging to a designed whole. Use parallel generation for single featured images on unrelated daily posts, site-wide batch fills, stock-style illustrations, and routine content where volume matters more than coherence.
Does this method only work with Gemini?
No. The method works with any image-capable model that supports persistent conversation context — meaning the model can see prior turns in the same conversation and use them when generating new images. Gemini handles this well today. Other models with similar capabilities work just as well. The principle is about conversation context, not about a specific provider.
What is the “seam test” for image set cohesion?
The seam test asks whether your images need to feel like one project when seen at a glance — like five views of the same world rather than five separate illustrations. If yes, sequential generation is the right method. If the images can stand alone without referencing each other, parallel generation is faster and equally good. The split between volume work and premium work follows the seam test.
Can I mix sequential and parallel generation in the same project?
Yes, and it often makes sense. Generate the cohesive set sequentially for the article’s main illustrations, then use parallel generation for one-off support images, thumbnails, or social variants that don’t need to share DNA with the main set. The methods are tools, not ideologies. Match the method to the cohesion requirement of each image.
The headline: In mid-May 2026, we ran an autonomous OpenRouter session querying 54 LLMs about their own identity, capabilities, and training. Total cost: $1.99 against a $270 starting balance. 43 substantive responses, 10 documented failures, 1 reasoning-only response. The most interesting finding: aion-2.0 identified itself as Claude — concrete evidence of training-data identity inheritance across LLMs. This article walks through the methodology, the reliability data, and what cheap multi-model research now makes possible.
This is part of our OpenRouter coverage. For the operator’s view on why we run model research through OpenRouter, see the field manual. For the structured decision methodology that multi-model setups also enable, see the roundtable methodology.
The setup
In mid-May 2026 we ran an autonomous session designed to extract self-knowledge from a wide sample of available LLMs. The question structure was simple: ask each model about its own identity, training, capabilities, and limits, then capture the response for cross-comparison.
The scope expanded mid-execution from the original 50 to 54 models — the OpenRouter catalog had grown during the session itself, which is its own data point about how fast this ecosystem moves.
The architecture: a Python script with parallel bash execution, a max-wait timeout per model, graceful per-provider error handling, and Notion publishing of each model’s response as a separate Knowledge Lab entry. Everything billed through OpenRouter.
The cost: $1.99 against a $270 starting balance. Less than two dollars to canvas 54 frontier and near-frontier models on a question of self-identity.
The hit rate
Of 54 models queried, 43 returned substantive responses. One returned a reasoning trace without final content (GPT-5.5 Pro, which we counted as a valid capture given the reasoning content was the interesting part). 10 returned documented failures.
That’s 81% substantive completion. For a fully autonomous run against a heterogeneous provider pool with no per-model tuning, that’s a meaningful number.
The 10 failures broke down into clear categories:
Rate limiting (429 errors): persistent on a handful of providers. Some had genuine quota issues; some appeared to be hitting upstream limits we couldn’t see from our side.
Forbidden (403): providers refusing the request entirely, often for reasons related to account configuration we hadn’t completed.
Not found (404): model IDs that had moved or been deprecated between our model-list scrape and the execution.
Timeouts: the most interesting category. Grok 4.20 multi-agent consistently exceeded our timeout window — not because it was slow, but because it appears to orchestrate sub-agents that genuinely take more than 40 seconds to produce a final answer. We documented this as a failure for our purposes; for a different use case it would have been a feature.
The decision we made in real time was not to retry persistent failures. If a provider returned 429 on three consecutive attempts, we let it stand as a documented failure rather than burning the run on retries. The rationale: those providers are either genuinely rate-limited or having an issue, and a fourth attempt in the same minute isn’t going to resolve either.
The finding that mattered
Of all the substantive responses, one stood out: aion-2.0 identified itself as Claude.
Not “trained on Claude data.” Not “fine-tuned from a Claude-derived model.” It described itself, in the first person, as Claude.
Aion-2.0 is not Claude. It’s a separate model from a separate provider. The most likely explanation is that its training data included a significant volume of Claude outputs, and the model’s self-knowledge inherited Claude’s identity along with Claude’s content patterns. The model learned to be Claude-like in style and, in the process, learned to identify as Claude in substance.
This is a known phenomenon in the literature on training data contamination, but seeing it surface concretely in a production model — on an answer to a basic self-identity question — is different from reading about it in a paper. It’s a real thing happening at scale, and most users of these models have no idea.
The implication for anyone running multi-model evaluations: model outputs are not independent. Models trained on the outputs of other models inherit not just style but identity, opinion patterns, and likely failure modes. If you’re running a roundtable methodology and treating three models as three independent perspectives, and one of them is silently downstream of another in training data, your “consensus” might be one model’s perspective dressed in three different costumes.
This is also an argument for why first-party model selection — choosing models from clearly distinct lineages rather than just “three frontier models” — matters more than people give it credit for.
The reliability data
Setting aside the aion-2.0 finding, the bare reliability data from this run is useful on its own terms.
10 of 54 providers (18.5%) returned errors. That’s a meaningful failure rate for any production workload that depends on cross-model availability. If your application assumes you can call any model in the catalog and get a response, you’re going to be wrong about 1 in 5 of the time on first attempt.
OpenRouter’s pooled access mitigates this somewhat — for some providers, OpenRouter automatically retries against alternate endpoints when one fails. But the failures we saw were after OpenRouter’s own retry logic ran. These are the failures that surface to the caller after the routing layer has done what it can.
For production systems, the practical implication is straightforward: never depend on any single model being available. Build fallback chains. Use OpenRouter’s Auto Router with a wildcard allowlist for tolerance, or wire your own fallback logic. A multi-model architecture isn’t a luxury; it’s a reliability requirement.
The cost shape
$1.99 of spend across 54 model queries works out to roughly $0.037 per query, including all the failed attempts.
That’s the headline number, but the distribution matters more than the average. A handful of queries — the ones that hit larger reasoning models like Claude Opus or GPT-5.5 Pro — accounted for the majority of the spend. Cheap models like Gemini Flash and various open-source mid-tier models barely moved the needle.
If you’re running research at this kind of breadth, the cost model is dominated by the heavy reasoning models, not by the long tail of cheaper models. The implication: when you’re running broad-canvas queries, it costs almost nothing to add another cheap model to the catalog. Adding another expensive reasoning model is what you should be deliberate about.
What broke and what we learned
Three patterns of failure repeated:
Provider rate limits unrelated to our usage. Some providers appear to share upstream capacity with the wider OpenRouter user base, and when that upstream capacity is hot, your individual call fails regardless of your own usage. There is no client-side fix. You either retry later or fall back.
Model IDs drift. The catalog moves fast. A model ID you fetch on Monday may have been deprecated by Friday. Our script’s freshness window — about a day between model-list scrape and execution — was sometimes enough for drift. For production systems, fetch the model list immediately before the run.
Multi-agent models exceed simple timeout windows. Grok 4.20’s behavior of orchestrating sub-agents that take 40+ seconds is not a bug; it’s the product. But it breaks any timeout shorter than what the multi-agent run actually needs. If you’re going to call multi-agent models, plan for long latencies and don’t share a timeout policy with single-call models.
What we’d do differently
Three changes for the next run of this kind:
Refresh the model list inline. Don’t trust a list scraped even a few hours earlier. Fetch fresh before each batch.
Tiered timeouts. Single-call models on a tight timeout. Multi-agent and reasoning-heavy models on a relaxed one. Detect which is which from the model metadata where possible.
Publish-as-you-go. Our Notion publish step ran after data collection. The session ended mid-publish, leaving uncertainty about which of the 54 pages had actually been created. Better to publish each result immediately as it returns, so a session interruption doesn’t lose anything.
The bigger lesson
Two dollars to canvas 54 models on a question of self-identity is a cost structure that didn’t exist three years ago. It also means a category of research that used to require expensive infrastructure is now within reach of anyone with an OpenRouter account and a Python script.
The interesting finding — aion-2.0 silently identifying as Claude — would have been almost impossible to discover any other way. You can’t catch a training-data identity inheritance by reading model documentation. You catch it by asking a lot of models the same question and looking at the answers side by side.
OpenRouter, for all its caveats and its limited scope, makes this kind of multi-model research tractable in a way nothing else currently does. If you’re not running periodic broad-canvas queries against your model catalog, you’re flying blind on what’s actually in there. Two dollars is cheap insurance against being surprised by the next aion-2.0.
Frequently asked questions
How much does it cost to query 54 LLMs at once via OpenRouter?
In our autonomous run, the total cost was $1.99 — roughly $0.037 per query including the 10 failed attempts. Cost was dominated by the few queries hitting expensive reasoning models like Claude Opus and GPT-5.5 Pro; the long tail of cheaper models barely moved the needle. Adding more cheap models to a broad-canvas query costs almost nothing.
What is training-data identity inheritance?
When a model’s training data includes outputs from another model, the trained model can inherit not just style but identity from the source model. In our run, aion-2.0 identified itself as Claude — likely because its training data contained enough Claude outputs that the model’s self-knowledge absorbed Claude’s identity along with Claude’s content patterns. This is a known phenomenon in the literature on data contamination.
How reliable are LLM providers via OpenRouter?
In our 54-model autonomous run, 10 providers (18.5%) returned errors after OpenRouter’s own retry logic ran. The failures broke down into rate limits, forbidden responses, deprecated model IDs, and timeouts on multi-agent models. The practical implication: never depend on any single model being available. Build fallback chains.
Why did some models timeout in the 54-LLM run?
The most notable timeout case was Grok 4.20 multi-agent, which appears to orchestrate sub-agents that genuinely take more than 40 seconds to produce a final answer. This isn’t a bug; it’s the product. But it breaks any timeout policy shared with single-call models. Multi-agent and reasoning-heavy models need their own relaxed timeout tier.
Should I run periodic broad-canvas queries against my model catalog?
Yes. At roughly two dollars per 54-model run, broad-canvas queries are cheap insurance against being surprised by training-data inheritance, identity drift, or quality degradation in models you depend on. You can’t catch these issues by reading documentation. You catch them by querying widely and comparing answers side by side.
The Multi-Model AI Roundtable is a three-round structured exchange where the same question is sent to three models from different lineages (typically Claude, GPT, and Gemini), cross-pollinated by sharing each model’s response with the others, and then synthesized into a final recommendation with explicit confidence calibration. Used for strategic decisions, content architecture, and technical trade-offs where single-model output isn’t trustworthy enough.
This is part of our OpenRouter coverage. See the operator’s field manual for the broader context on why we route through OpenRouter, and the 5-layer mental model for the hierarchy that makes multi-model routing tractable.
Why three models beat one
Single-model decision-making has a known failure mode: the model’s training data and reasoning patterns silently shape every recommendation. The model doesn’t know what it doesn’t know. You don’t know what it doesn’t know. You get a confident answer, you act on it, and the missing perspective shows up later as a problem you didn’t see coming.
Three models from three different lineages catch each other’s blind spots. Claude Opus 4.7 tends to over-index on safety considerations and structural rigor. GPT-5.5 tends to favor decisive, action-oriented framing. Gemini 3 Flash tends to surface edge cases and multimodal context the others gloss over. Run a hard decision past all three and the agreement-versus-disagreement pattern itself becomes information.
The methodology we use is a three-round structured exchange. Same question, three responses, then cross-pollination, then synthesis. Below is the exact pattern we’ve used across decisions ranging from tech stack choices to keyword prioritization to architectural calls on the autonomous behavior system.
The architecture
OpenRouter makes this cheap to wire. One API endpoint, three different model identifiers, three parallel calls:
That’s the entire architectural surface. Three calls, three responses, parallel execution. Without OpenRouter you’d be juggling three separate API contracts. With it, one endpoint and a model parameter.
Round 1: Individual perspectives
Send the same question to all three models with no awareness that they’re part of a roundtable. Each responds independently.
The prompt structure that works:
We’re evaluating [decision]. Consider:
The key factors to weigh
Risks and mitigations
Your recommendation, with reasoning
What you might be missing
The fourth bullet is the one that earns the cost of the call. Asking a model to name its own blind spots is a remarkably effective way to surface the limits of its perspective. Models that handle this prompt well will name epistemic limits explicitly: “I don’t have visibility into your team’s specific constraints,” or “this depends on factors I can’t verify from this conversation.”
Collect all three Round 1 responses. Don’t synthesize yet.
Round 2: Cross-pollination
This is where the methodology earns its keep. Send each model the other two models’ Round 1 responses and ask:
Identify points of agreement
Challenge or refine the other perspectives
Update your own recommendation if warranted
Most teams skip this round. They run Round 1, see agreement, ship a decision. They miss the cases where one model would have changed its mind given the other models’ input — which is exactly the cases where the disagreement matters.
Round 2 also surfaces a pattern worth naming: model deference. Some models, when shown a different perspective, will pivot toward it almost regardless of the merits. Others hold their position too rigidly. Watching how each model handles disagreement is itself information about how to weight their inputs in future roundtables.
Round 3: Synthesis
One model — usually Claude in our case, because long-form reasoning is the job — gets all the Round 1 and Round 2 outputs and produces a final synthesis:
Consensus points (where all three models agreed, both rounds)
Remaining disagreements (where the models did not converge)
Confidence level (high if convergence, medium if mixed, low if persistent disagreement)
Suggested next steps
The confidence calibration is the part that changes how decisions actually get made. A decision the roundtable converges on with high confidence can be acted on immediately. A decision with persistent disagreement is a signal that the question is harder than it looked, and probably needs human judgment or more research before action.
When this is worth running
The roundtable is not free. Three rounds, three models, plus synthesis equals roughly four to six API calls per decision. Even at low-cost model pricing for the initial rounds, this adds up if you run it on every micro-decision.
Use it for:
Strategic decisions — tech stack selection, business model choices, pricing strategy
Content strategy at scale — keyword prioritization for a 50-article batch, topic cluster architecture, format decisions
Technical architecture — system design, security posture, performance trade-offs
Anything irreversible — moves that you’ll wear for months if they’re wrong
Don’t use it for:
Day-to-day operational questions a single model can answer well
Decisions where you already know the answer and just want validation
Questions where the cost of being wrong is small
Cost shape
For an agency stack the cost-per-roundtable comes out roughly as follows when using a balanced model mix:
Round 1: three parallel calls. Use Gemini 3 Flash or DeepSeek V3.2 for breadth at low cost. Heavier models only when you need deeper reasoning in Round 1.
Round 2: three more calls with more context. Same models, larger context window.
Round 3: one synthesis call. Use the best reasoning model you have access to — Claude Opus 4.7 is our default for synthesis.
Total cost per decision typically runs from a few cents to a few dollars depending on context length and model selection. For decisions worth running through the roundtable, that’s noise.
An example output
A real roundtable from our archive, on the question of where to start with Google Apps Script as a learning project:
GPT-5.5: Start simple — a Google Sheets data retrieval script. Learning value comes from working through the auth flow and basic API surface without complexity getting in the way.
Claude Opus 4.7: Start impactful — a Time Insight Dashboard combining Gmail and Calendar data. Higher learning curve but produces something you’ll actually use, which keeps motivation up.
Gemini 3 Flash: Hybrid — simple foundation but with one meaningful integration. Lowers the activation energy while preserving the impact angle.
Consensus (Round 3): Begin with a data retrieval script (all three models agree on the learning value) but include one meaningful integration like calendar events. The Round 2 cross-pollination resolved most of the disagreement; Claude moderated its position after seeing GPT-5.5’s argument about activation energy.
Confidence: High. All three models aligned on progressive complexity after cross-pollination.
That output is more useful than any single model’s recommendation would have been. It names the trade-off, shows the path to consensus, and quantifies confidence. That’s what you’re paying for.
The variations worth knowing
A few patterns we’ve adapted from the base methodology:
Adversarial roundtable. Instead of asking each model the same question, assign roles. Model A argues for. Model B argues against. Model C judges. Useful for decisions where you suspect you’ve already made up your mind.
Sequential expert chain. Skip parallel Round 1. Run one model, then send its output to the next model to refine, then to the third. Slower but useful when you need each step to build on the last.
Domain-specialized roundtable. Use BYOK to route Round 1 calls to specialty providers when the question is technical. A legal question routes through a legal-specialized provider. A code question routes through a code-specialized provider. The synthesis still happens at Claude Opus 4.7 or GPT-5.5.
The base methodology — three rounds, three models, one synthesis — is the version we run by default. The variations are for cases where the base pattern is leaving value on the table.
What this unlocks
Once the roundtable is wired into your stack, a category of decision that used to take a meeting becomes a 90-second API call. Not every meeting. The ones where you would have walked in already knowing the answer and the meeting was performative.
The roundtable doesn’t replace human judgment. It replaces the version of the decision where you didn’t think it through. The version where you would have shipped your first instinct and lived with the consequence. That’s the win.
Frequently asked questions
What is a multi-model AI roundtable?
A three-round structured exchange where the same question is sent to three AI models from different lineages, then cross-pollinated by sharing each model’s response with the others, then synthesized into a final recommendation with explicit confidence calibration. The methodology surfaces blind spots that single-model output silently hides.
Why use Claude, GPT, and Gemini together instead of just one?
Each model has different training data and reasoning patterns. Claude tends to emphasize safety and structural rigor. GPT tends to favor decisive action-oriented framing. Gemini tends to surface edge cases. Running a hard decision past all three gives you agreement-versus-disagreement information that no single model can provide.
How much does a multi-model roundtable cost per decision?
Typically a few cents to a few dollars per decision, depending on model selection and context length. Using cheaper models (Gemini Flash, DeepSeek) for the initial rounds and reserving the expensive reasoning models for Round 3 synthesis keeps the cost shape favorable.
When is the multi-model roundtable not worth running?
Skip it for day-to-day operational questions a single model can answer well, decisions where you already know the answer and just want validation, and questions where the cost of being wrong is small. Reserve it for strategic decisions, content architecture, technical trade-offs, and anything irreversible.
What is the third round of the roundtable for?
Synthesis. One model — typically the strongest reasoning model in the set — receives all the Round 1 and Round 2 outputs and produces a final recommendation with consensus points, remaining disagreements, confidence level, and suggested next steps. This is the part that turns three opinions into one actionable decision.
BYOK on OpenRouter: Bring-Your-Own-Key on OpenRouter means configuring direct provider credentials for any of dozens of supported providers, with per-provider prioritization, fallback chains, and the ability to pin specific BYOK keys to specific OpenRouter API keys (meaning specific agents). The result is a routing system where you can mix discounted enterprise contracts with pooled access, transparent to the calling code.
This is a deep dive on the BYOK system inside OpenRouter. For the broader operator’s perspective on OpenRouter, see our OpenRouter operator’s field manual. For the underlying hierarchy that governs where BYOK lives, see the 5-layer mental model.
What BYOK actually means here
Most platforms use “BYOK” to mean bring your key for the one provider we support. OpenRouter means something more interesting: bring your key for any of dozens of providers, configure prioritization and fallback per provider, pin keys to specific agents and models, and let OpenRouter handle the routing logic when a key fails or runs out.
The result is a routing system where you can mix and match. Run your high-volume agent through a discounted enterprise contract at Provider A. Route everything else through OpenRouter’s pooled pricing. Fall back to OpenRouter’s pool when your enterprise key is rate-limited. All transparent to the calling code.
This is genuinely useful for an agency stack. It’s also where most teams misconfigure things in ways that don’t fail loudly.
The Providers tab
This is where the bulk of BYOK lives. Every provider — from AI21 at the top of the alphabet to Z.ai at the bottom — gets its own configuration card. Each card has two slots: Prioritized keys (tried first, before falling back to OpenRouter’s pooled access) and Fallback keys (tried last, after everything else fails).
Per-key configuration is granular. Each key has:
A name (free text — use it well, you’ll thank yourself later)
The API key value itself
An “Always use for this provider” toggle that disables OpenRouter’s pooled fallback entirely for calls routed through this key
Filters: Models (All, or a specific subset) and API Keys (All OpenRouter API keys, or a specific subset)
The filter system is the part most teams miss. You can pin a BYOK key to specific OpenRouter API keys, meaning specific agents. Read that twice. It means a single BYOK key can be the routing target for exactly one agent’s calls, while every other agent on the workspace continues using pooled access.
This unlocks a powerful pattern for agency work: a client who has their own enterprise contract with a model provider can have their work routed exclusively through that contract, billed to that contract, while your other clients use pooled pricing. The routing happens at the provider layer, invisibly to the calling code.
Prioritization and fallback in practice
Here’s the order of operations OpenRouter uses when you call a model:
Is there a Prioritized BYOK key for this provider, this model, and this calling key? Use it.
If that key has “Always use for this provider” enabled, return any failure as-is. Don’t fall back.
Otherwise, fall back to OpenRouter’s pooled access.
If that fails too, try any Fallback BYOK keys configured for this provider.
If everything fails, return the error.
The “Always use for this provider” toggle is a sharp edge. Enabling it means a single failed enterprise contract — expired credentials, network issue at the provider, momentary rate limit — becomes a hard failure for every call routed through that key. Disabling it gives you graceful degradation but means your enterprise contract isn’t strictly enforced.
Our pattern: enable “Always use” only for clients with hard data-policy requirements (no third-party touching of their data, ever). For everyone else, leave it disabled and let OpenRouter’s pooled access catch the failures.
The Web Search slot (Firecrawl)
The Providers tab has a second section that isn’t strictly BYOK: workspace-level Firecrawl integration. OpenRouter partnered with Firecrawl to provide 10,000 free credits per workspace, with a three-month expiry, contingent on accepting Firecrawl’s Terms of Service.
This is wired at the workspace level, not per-key. Once accepted, any plugin that uses Web Search inherits the Firecrawl integration. Cheap, useful, easy to forget you enabled it.
The mistake to avoid: assuming the 10,000 credits are forever. Three months. If you’re going to depend on this, plan for renewal.
How to think about provider selection
The temptation with dozens of providers is to spin up BYOK keys for every model you might ever want. Don’t.
Start with three categories:
Volume providers — the ones you call most. For us that’s Anthropic (Claude family) and Google (Gemini family). Worth getting BYOK keys for these even if you don’t have an enterprise contract; it makes the routing explicit and the costs auditable.
Specialty providers — ones you call for specific jobs. We use OpenAI for some specific reasoning tasks. We use specialized model providers (Stepfun, others) for niche work. BYOK keys here only if you have a contract worth routing through.
Experimental providers — everything else. Don’t bother with BYOK. Use OpenRouter’s pooled access. If a model from one of these providers becomes a regular part of your workflow, promote it to specialty.
The audit story
In March 2026 we ran a security audit on 122 Cloud Run services and discovered five of them had hardcoded OpenRouter keys in their environment variables — same key across all five. We stripped them, rotated, and re-scanned to zero.
That was an OpenRouter key, not a BYOK provider key, but the lesson generalizes: API keys do not belong in environment variables on shared infrastructure. They belong in a secret manager with audited access. GCP Secret Manager, AWS Secrets Manager, HashiCorp Vault — pick one and use it.
The standing rule we wrote afterward applies equally to BYOK provider keys: any key, any provider, any environment, lives in a secret manager. Period.
Pinning keys to agents: the operational unlock
The BYOK feature most teams underuse is the per-key filter system. You can configure a BYOK provider key to be used only by specific OpenRouter API keys.
This sounds abstract until you map it to a real workflow:
Your content production agent runs through OpenRouter key A
Your customer support bot runs through OpenRouter key B
Your enterprise client has a contract with Anthropic and wants their work routed through that contract
You create a BYOK Anthropic key for the enterprise contract. In the BYOK key’s filter, you specify “API Keys: only OpenRouter key C” (the key used by the agent serving that client). Now content production (key A) and customer support (key B) use OpenRouter’s pooled access. The enterprise client’s agent (key C) routes through the enterprise contract.
No code changes. No service restarts. Just routing config at the provider layer.
This is the kind of pattern that pays for OpenRouter’s existence in the stack. Most teams discover it only after they’ve outgrown a simpler setup. Start with it from day one if your shape looks anything like an agency.
What to do today
If you’re getting started with BYOK on OpenRouter:
Identify the two or three providers you call most. Get BYOK keys for those.
Store every key in a secret manager. Not in code. Not in env vars on shared infra.
Use the per-key filter system from the start. Don’t let one BYOK key get used by every agent unless you actually want that.
Leave “Always use for this provider” off unless you have a hard policy reason to enforce it.
Set a calendar reminder for any time-limited credits (looking at you, Firecrawl).
The BYOK system is one of the genuinely useful features on the platform. Treat it like the routing layer it is, not like a credentials dump, and it’ll pay for the setup time many times over.
Frequently asked questions
What is BYOK on OpenRouter?
BYOK (Bring-Your-Own-Key) on OpenRouter means configuring direct provider credentials for any supported provider. OpenRouter then routes calls through your provider key instead of (or before falling back to) its pooled access. You can configure prioritization, fallback chains, and per-agent pinning.
Should I use BYOK on OpenRouter even without an enterprise contract?
For the providers you call most, yes. Even without a discount, BYOK makes the routing explicit and the costs auditable on your provider’s billing rather than buried in OpenRouter’s aggregate. For providers you barely call, don’t bother — OpenRouter’s pooled access is simpler.
What does “Always use for this provider” actually do?
It disables OpenRouter’s pooled fallback for any call routed through that BYOK key. If your enterprise contract fails for any reason — expired credentials, rate limit, network issue — the call returns the error instead of silently falling back to OpenRouter’s pool. Useful for hard data-policy requirements; risky for general reliability.
Can I pin a BYOK key to specific agents?
Yes. The per-key Filters section lets you specify which OpenRouter API keys (meaning which agents) can route through this BYOK key. This unlocks the pattern of running one client’s work through their enterprise contract while every other agent uses pooled access — all transparent to the calling code.
How should I store BYOK provider keys?
In a secret manager — GCP Secret Manager, AWS Secrets Manager, HashiCorp Vault. Never in environment variables on shared infrastructure. We learned this from a March 2026 audit that found five Cloud Run services with hardcoded keys baked into env vars. Standing rule now: any key, any provider, any environment, lives in a secret manager.
The OpenRouter hierarchy in one sentence: Organizations contain Workspaces, Workspaces enforce Guardrails on API Keys, Keys call Presets, and Presets bundle prompts and models. Every operational decision you’ll ever make on the platform lives at exactly one of those five layers. Confuse them and you’ll spend hours looking for settings that live somewhere other than where you think.
This is a companion to our OpenRouter operator’s field manual. The field manual covers why we use the platform and how it fits a fortress stack. This deep dive covers the mental model itself — the five-layer hierarchy that makes everything else legible.
Why this matters before anything else
OpenRouter’s UI presents a flat menu. The actual product is a hierarchy. Every operational decision you’ll ever make — who pays, what’s allowed, who’s allowed to call what, which model gets used — lives at exactly one of five layers. Get the layers wrong and you’ll wire your stack against the wrong nouns.
The five layers, top to bottom: Organization → Workspace → Guardrail → API Key → Preset.
Here’s what each one actually does and when you should care.
Layer 1: Organization
Sovereign billing. Sovereign member context. The top of the world.
Each Organization has its own balance, its own billing details, and — critically — its own member roster. The catch: personal orgs don’t expose Members management. If you want to add teammates, you need a non-personal org.
In our case we run two: a personal org tied to our primary email, and a Tygart Media org for agency operations. The personal org has 48 API keys and a working balance. The Tygart Media org is empty so far. Members management is the reason it exists.
When to think about this layer: when you’re deciding whether to operate as an individual or as a team. If you’re solo and plan to stay solo, one personal org is fine forever. The moment you bring on a collaborator who needs their own keys and their own observability slice, you need a non-personal org.
The mistake to avoid: running an agency out of a personal org. You’ll hit member-management limits at the worst possible time.
Layer 2: Workspace
Segmented guardrail, BYOK, routing, and preset domains inside an organization.
By default, every org gets one Default Workspace. Most accounts never think about this layer. The moment you operate across multiple businesses with different data policies, multiple workspaces become valuable.
Example: a healthcare client’s data should never touch first-party Anthropic, only Bedrock or Vertex. A consumer comedy site can use any provider. A B2B SaaS client wants Zero Data Retention enforced on every call. Three different fortress postures. Three workspaces.
Each workspace gets its own Guardrail config, its own BYOK provider keys, its own routing defaults, and its own preset library. Keys created in one workspace can’t see resources in another.
When to think about this layer: when you have two or more clients with materially different data policies. If everything you do has the same posture, one workspace is fine.
The mistake to avoid: assuming workspace segmentation is a security boundary. It isn’t, exactly — it’s a policy boundary. Someone with org-level access can move between workspaces freely. Workspaces are for organizing intent, not for isolating threats.
Layer 3: Guardrails
The actual enforcement layer. Four categories, all configurable per workspace, all unconfigured by default.
Budget Policies are the most useful and the most underused. Set a credit limit in dollars and a reset cadence (Day, Week, Month, Year, or N/A). Hit the limit and calls fail until the cadence resets. This is your protection against the runaway loop that drains a balance overnight.
Model and Provider Access is where data-policy posture lives. Toggles for Zero Data Retention enforcement, Non-frontier ZDR, first-party Anthropic on or off (with Bedrock and Vertex always staying available), first-party OpenAI on or off (Azure stays), Google AI Studio on or off (Vertex stays), and three categories of paid and free endpoints with different training and publishing behaviors. There’s also an Access Policy mode (Allow All Except is the useful one) with explicit Blocked Providers and Blocked Models lists. The live Eligibility view shows you which providers and models are actually callable given your current policy.
Prompt Injection Detection runs regex-based detection on inbound prompts. OWASP-inspired patterns. Four modes: Disabled, Flag, Redact, or Block. Free and adds no measurable latency. Worth enabling on every workspace that touches user input.
Sensitive Info Detection runs pattern matching on prompts and completions. Built-in patterns for Email, Phone, SSN, Credit Card, IP address, Person Name, and Address. The latter two add latency. Custom regex patterns supported. A sandbox to test patterns before deploying. Useful for any workspace that processes customer data.
When to think about this layer: every workspace, day one. Default-unconfigured is not a safe state. Set a budget cap before you do anything else.
The mistake to avoid: treating Guardrails as something you’ll get to “later.” Later is after the runaway loop has drained the balance.
Layer 4: API Keys
Per-agent identity. Each key has its own credit cap, its own reset cadence, and its own guardrail overlay.
The mental model that matters: one autonomous behavior, one key. When a scheduled task starts hemorrhaging tokens, the cap on its key contains the damage. The other 47 keys keep working.
Our 48-key distribution is instructive. One testing key has spent $83.26. One development key has spent $33.05. The remaining 46 keys have collectively spent less than $120. That’s the shape of real AI operations: a few keys do most of the work, and a long tail barely moves the needle. Per-key caps make that distribution visible and bounded.
API keys also carry the BYOK relationship. A bring-your-own provider key can be pinned to specific API keys, meaning specific agents. That lets you route a high-volume internal agent through a discounted enterprise contract while letting one-off testing keys fall through to OpenRouter’s pooled pricing. We cover this in depth in BYOK on OpenRouter.
When to think about this layer: when you create any new autonomous behavior. New behavior, new key, new cap. No exceptions.
The mistake to avoid: sharing one key across all your services. The first runaway loop will be the last thing that one key ever does, and the blast radius will be everything else that depended on it.
Layer 5: Presets
Versioned bundles of system prompt, model, parameters, and provider configuration. Called as "model": "@preset/your-preset-name" in any API call.
Three tabs per preset: Configuration (the actual bundle), API Usage (how it’s been called), and Version History (every change, rollback-able).
This is the closest OpenRouter comes to a software release artifact. You can ship a preset, test it in chat, version it, and roll back if v2 turns out to be worse than v1. Code that calls the preset stays the same; only the preset content changes.
For autonomous behavior systems this is the unlock. A behavior’s behavior — its prompt, its model choice, its temperature — becomes a thing you can version and review like code, without touching the code that calls it. Promotion ledger says a behavior is graduating from one tier to the next? You publish a new preset version with tighter constraints and the calling code never changes.
When to think about this layer: the moment you have any system prompt that’s used in more than one place, or that you’ll want to refine over time. If you’ve never copy-pasted a system prompt between two scripts, you don’t need presets yet.
The mistake to avoid: putting the system prompt in the calling code. Every prompt update becomes a deploy. With presets, prompt updates become config changes.
Putting the layers together
Here’s the mental model in one sentence: Organizations contain Workspaces, Workspaces enforce Guardrails on Keys, Keys call Presets, Presets bundle prompts and models.
If you walk into OpenRouter looking for a setting and you can’t find it, ask which of the five layers it should logically live at. The answer almost always tells you where to look.
If you’re building a new integration, start at the bottom. Pick a model. Build a preset around it. Create a dedicated key with a tight budget cap. Sit that key under a workspace with sensible guardrails. The organization is just the billing wrapper.
The whole point of the hierarchy is that each layer constrains the one below it. The organization caps the workspace. The workspace caps the keys. The keys cap the presets they can call. Errors propagate up; permissions cascade down. That’s the model. Everything else is UI.
Frequently asked questions
What are the five layers of OpenRouter?
Organization, Workspace, Guardrails, API Keys, and Presets. Organizations handle billing and members. Workspaces segment policy domains. Guardrails enforce budget, provider access, prompt injection, and sensitive info rules. API Keys are per-agent identity with per-key caps. Presets are versioned bundles of system prompt, model, and parameters.
Do I need multiple Workspaces in OpenRouter?
Only if you operate across businesses with materially different data policies. A single Default Workspace is fine for most accounts. The moment a healthcare client requires Bedrock-only access while a consumer client can use any provider, workspace segmentation becomes valuable.
What is the right way to use OpenRouter Presets?
Treat them like software release artifacts. Bundle the system prompt, model, parameters, and provider config. Version every change. Test new versions in chat before promoting. Code that calls the preset stays the same; only the preset content evolves. This lets you refactor prompt behavior without redeploying.
Are OpenRouter Workspaces a security boundary?
No. They’re a policy boundary, not a security boundary. Someone with organization-level access can move between workspaces freely. Use workspaces to organize intent and enforce different fortress postures across clients — not to isolate threats from each other.
What happens if I don’t configure OpenRouter Guardrails?
By default every workspace has zero enforced budget cap, zero provider restrictions, and zero PII filtering. That’s fine for prototyping. It’s not fine for production. Set a budget cap on every workspace as the first action. The other three guardrail categories you can configure as you scale.