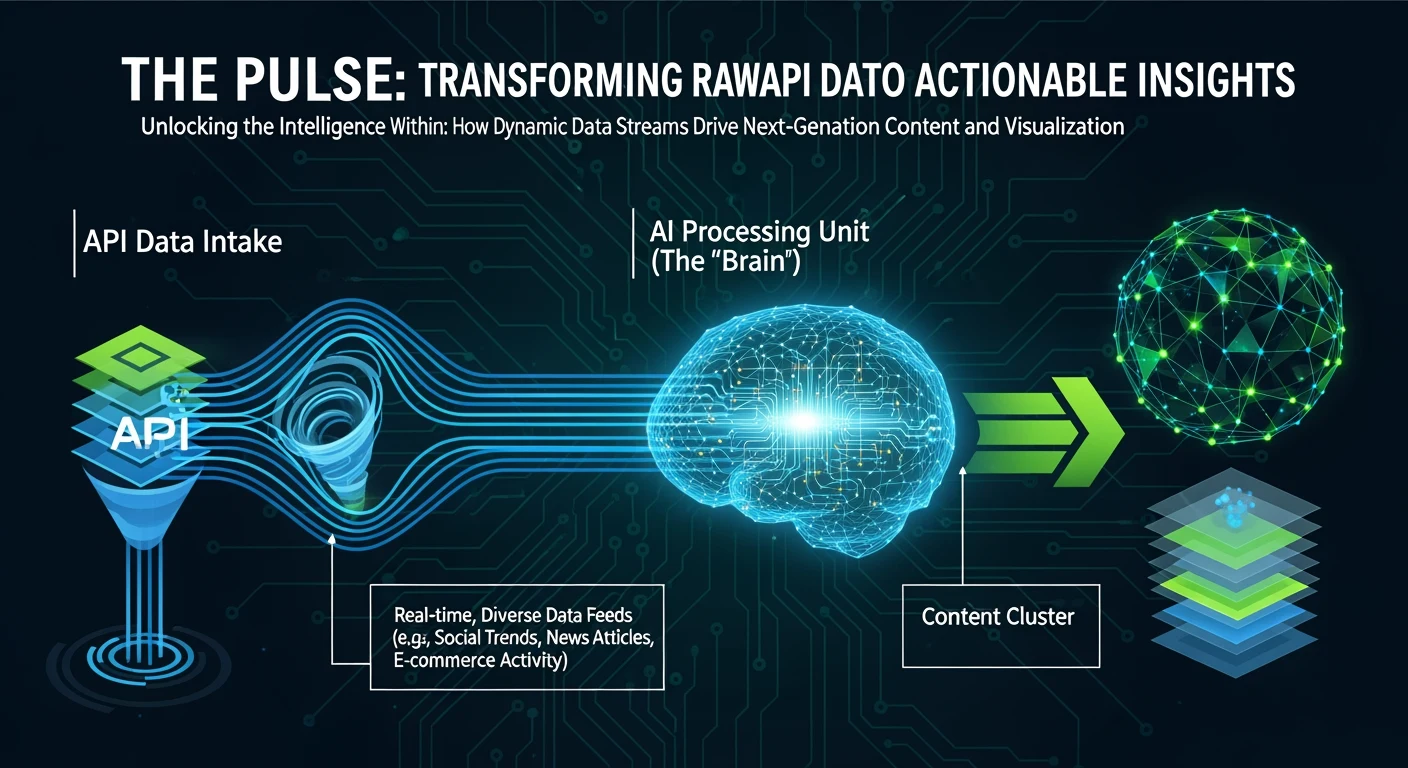
We used to pay for SEMrush, Ahrefs, and Moz. Then we discovered we could use the DataForSEO API with Claude to do better keyword research, at 1/10th the cost, with more control over the analysis.
The Old Stack (and Why It Broke)
We were paying $600+ monthly across three platforms. Each had different strengths—Ahrefs for backlink data, SEMrush for SERP features, Moz for authority metrics—but also massive overlap. And none of them understood our specific context: managing 19 WordPress sites with different verticals and different SEO strategies.
The tools gave us data. Claude gives us intelligence.
DataForSEO + Claude: The New Stack
DataForSEO is an API that pulls real search data. We hit their endpoints for:
– Keyword search volume and trend data
– SERP features (snippets, People Also Ask, related searches)
– Ranking difficulty and opportunity scores
– Competitor keyword analysis
– Local search data (essential for restoration verticals)
We pay $300/month for enough API calls to cover all 19 sites’ keyword research. That’s it.
Where Claude Comes In
DataForSEO gives us raw data. Claude synthesizes it into strategy.
I’ll ask: “Given the keyword data for ‘water damage restoration in Houston,’ show me the 5 best opportunities to rank where we can compete immediately.”
Claude looks at:
– Search volume
– Current top 10 (from DataForSEO)
– Our existing content
– Difficulty-to-opportunity ratio
– PAA questions and featured snippet targets
– Local intent signals
It returns prioritized keyword clusters with actionable insights: “These 3 keywords have 100-500 monthly searches, lower competition in local SERPs, and People Also Ask questions you can answer in depth.”
Competitive Analysis Without the Black Box
Instead of trusting a platform’s opaque “difficulty score,” we use Claude to analyze actual SERP data:
– What’s the common word count in top results?
– How many have video content? Backlinks?
– What schema markup are they using?
– Are they targeting the same user intent or different angles?
– What questions do they answer that we don’t?
This gives us real competitive insight, not a number from 1-100.
The Workflow
1. Give Claude a target keyword and our target site
2. Claude queries DataForSEO API for volume, difficulty, SERP data
3. Claude pulls our existing content on related topics
4. Claude analyzes the competitive landscape
5. Claude recommends specific keywords with strategy recommendations
6. I approve the targets, Claude drafts the content brief
7. The brief goes to our content pipeline
This entire workflow happens in 10 minutes. With the old tools, it took 2 hours of hopping between platforms.
Cost and Scale
DataForSEO is billed per API call, not per “seat” or “account.” We do ~500 keyword researches per month across all 19 sites. Cost: ~$30-40. Traditional tools would cost the same regardless of usage.
As we scale content, our tool cost stays flat. With SEMrush, we’d hit overages or need higher plans.
The Limitations (and Why We Accept Them)
DataForSEO doesn’t have the 5-year historical trend data that Ahrefs does. We don’t get detailed backlink analysis. We don’t have a competitor tracking dashboard.
But here’s the truth: we never used those features. We needed keyword opportunity identification and competitive insight. DataForSEO + Claude does that better than expensive platforms because Claude can reason about the data instead of just displaying it.
What This Enables
– Continuous keyword research (no tool budget constraints)
– Smarter targeting (Claude reasons about intent)
– Faster decisions (10 minutes instead of 2 hours)
– Transparent methodology (we see exactly how decisions are made)
– Scalable to all 19 sites simultaneously
If you’re paying for three SEO platforms, you’re probably paying for one platform and wasting the other two. Try DataForSEO + Claude for your next keyword research cycle. You’ll get more actionable intelligence and spend less than a single month of your current setup.
{
“@context”: “https://schema.org”,
“@type”: “Article”,
“headline”: “DataForSEO + Claude: The Keyword Research Stack That Replaced 3 Tools”,
“description”: “DataForSEO API + Claude replaces $600/month in SEO tools with $30/month API costs and better analysis. Here’s the keyword research workflow we built.”,
“datePublished”: “2026-03-30”,
“dateModified”: “2026-04-03”,
“author”: {
“@type”: “Person”,
“name”: “Will Tygart”,
“url”: “https://tygartmedia.com/about”
},
“publisher”: {
“@type”: “Organization”,
“name”: “Tygart Media”,
“url”: “https://tygartmedia.com”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://tygartmedia.com/wp-content/uploads/tygart-media-logo.png”
}
},
“mainEntityOfPage”: {
“@type”: “WebPage”,
“@id”: “https://tygartmedia.com/dataforseo-claude-the-keyword-research-stack-that-replaced-3-tools/”
}
}