
Most teams generate images for multi-piece content one API call at a time. The result is a set that shares general aesthetics but loses visual DNA at the seams. This article makes the case for generating cohesive image sets in one conversation context instead — and shows what each method actually produces.
Sequential vs parallel image generation: Sequential generation creates multiple images inside one conversation with an image-capable model, so each image inherits visual DNA — palette, perspective, geometric language, compositional rhythm — from the prior images in the same context window. Parallel generation creates each image in a separate API call, with no shared context, producing sets that share keywords but not feel. Use sequential for cohesive image sets where the visual identity matters; use parallel for high-volume independent images.

The image above is a simple visual contrast — one workflow on the left, a different workflow on the right, with an arrow pointing from one to the other. It’s also the kind of image you can only get reliably when you generate it as part of a series, in conversation with a model that already knows what visual language you’re working in. Generated cold, in isolation, the result drifts. Generated in context, alongside five other images sharing the same DNA, the result locks in.
This article is about why that happens, what it means for content production, and when to use which method.
What “in one context” actually means
When you generate an image with a typical API call, the model receives your prompt with no memory of any prior image. Each call is a cold start. The model interprets your style instructions from scratch every time. If you ask for “isometric perspective, dark navy background, cyan and amber accents” five times in a row, you’ll get five images that broadly match those words — but they won’t actually share visual DNA. They’ll share keywords.
When you generate in a single conversation with an image-capable model like Gemini, every image you’ve already made stays in the context window. The model sees what it just generated. The next image inherits the palette, the geometric vocabulary, the compositional rhythm, the lighting treatment, the specific aesthetic flavor of the prior images — not because you re-described those things, but because the model is continuing a project, not starting a new one.
That distinction sounds small. The output difference is large.
The conventional pipeline that produces parallel generation
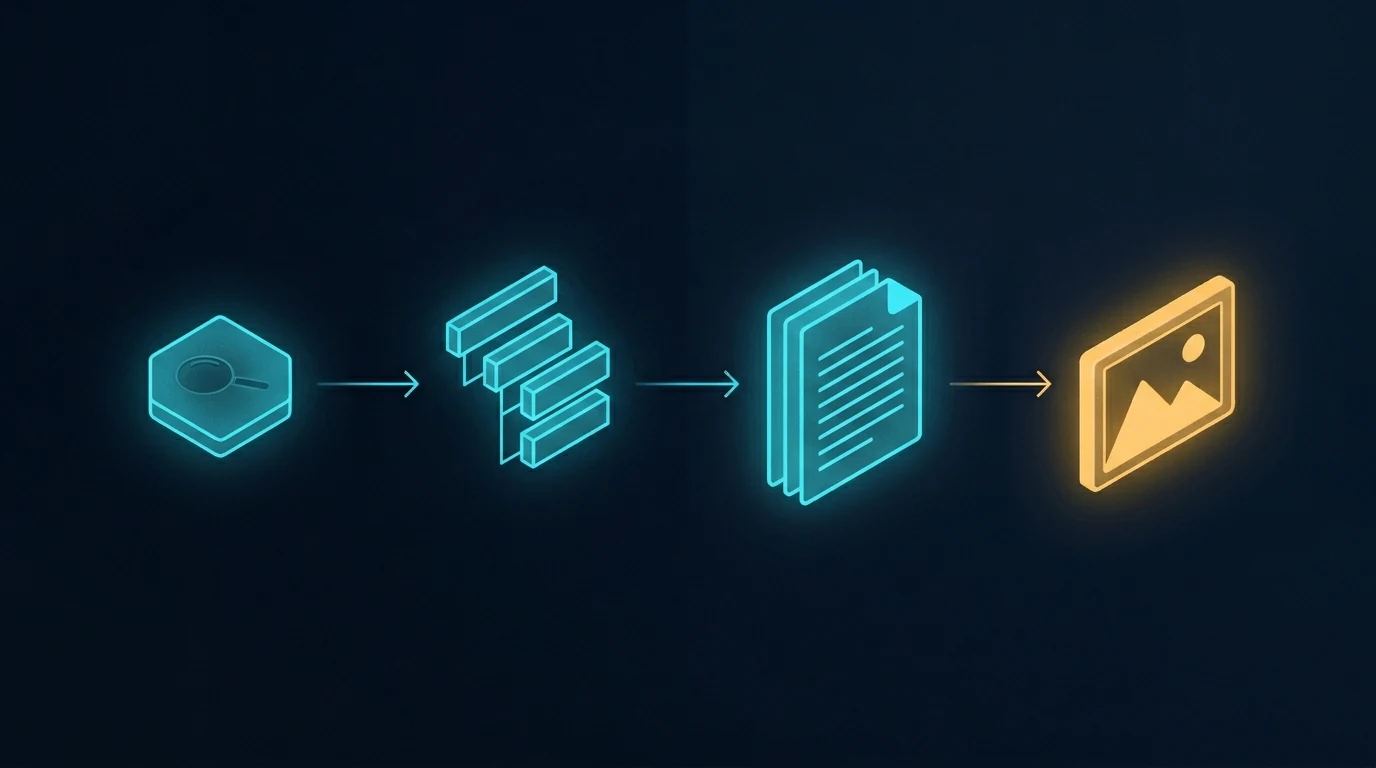
The image above shows the standard content pipeline. Research the topic, outline the structure, write the document, generate an image to go with it. When the article needs more than one image, the last step gets parallelized — multiple API calls fired in sequence or in parallel, each one a separate request, each one independent of the others.
This is how every CMS template works, how every batch image pipeline is built, and how most automated content systems run. It’s efficient. It’s fast. It scales to hundreds of images across hundreds of unrelated posts. And it’s exactly the right tool for that volume work.
It is not the right tool when the images are meant to belong to each other.
What parallel generation actually looks like

The image above shows the contrast plainly. Six frames, each containing a different abstract composition. They share a general aesthetic because the prompts asked for it — there’s a recognizable common style budget. But look at the actual visual content: one frame leans cool cyan, another leans warm amber, one uses hexagonal circuit patterns, another uses soft organic blobs, another uses sharp angular fragments. The compositional logic drifts. The palette drifts. There are no threads between them because there’s nothing connecting them in the model’s understanding.
This is what parallel image generation produces, even with carefully written prompts. Each call follows instructions in isolation. Each call invents its own interpretation of “dark navy with cyan and amber accents.” The instructions don’t lie — every frame is technically dark navy with cyan and amber — but the feel drifts because there’s nothing keeping it locked.
A reader scrolling past doesn’t consciously notice. They just feel, vaguely, that the images don’t quite belong together. That vague feel is the cost.
What sequential generation produces
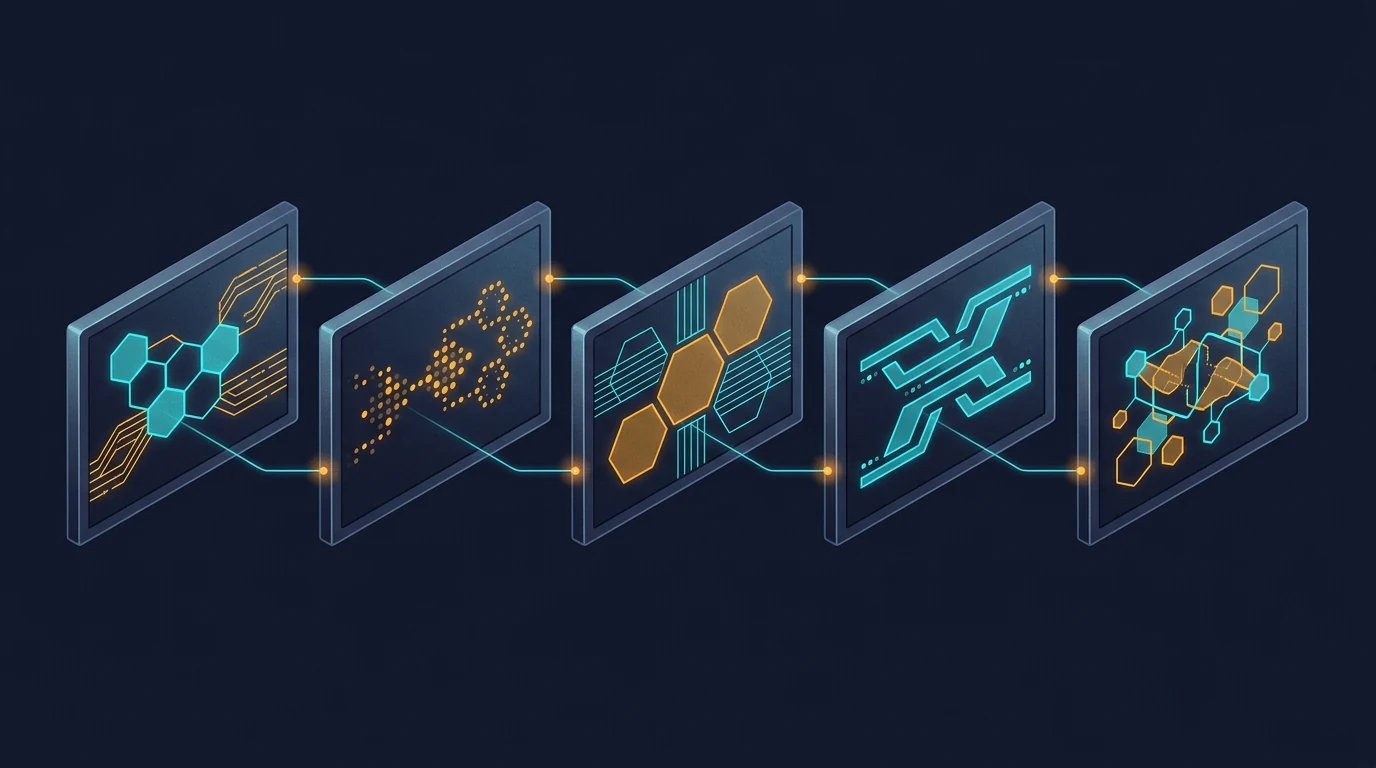
The image above shows the difference. Five frames, all generated in a single conversation. The visual continuity is immediately obvious — every frame uses the same palette, the same geometric vocabulary (hexagons, circuit traces, glowing nodes), the same compositional rhythm, the same slightly-elevated isometric perspective. The frames are different from each other in content — they’re not duplicates — but they belong to the same designed system.
The connecting threads in the image are the metaphor. Visual DNA flows from one frame to the next. The model doesn’t reinvent the aesthetic on frame two; it continues it. By frame five, the system has cohered so tightly that the model is generating within a style rather than generating to a style.
This is what context does. Every image you generate in that conversation is one more anchor point. The model has more to reference and less to invent. The fifth image is easier to make than the first, because the context has already done most of the work of specifying what the image should be.
The seam test
Here’s the practical diagnostic for whether your image set needs sequential generation: imagine the images displayed next to each other, maybe in a carousel or a grid, maybe as featured images for a series of related articles. Imagine a reader seeing them at a glance.
Do the images need to feel like one project? Like five views of the same world?
If yes, sequential generation is the right method. If the images can stand alone without referencing each other — a featured image on a daily blog post, a stock illustration for a generic article — parallel generation is fine and probably better. Speed and throughput matter more than coherence when nothing depends on coherence.
The volume tier and the premium tier of image production are doing different jobs. Treating them like one tier and reaching for parallel generation by default is how most teams end up with image sets that almost work.
How to actually do sequential generation
The method is mechanical and worth spelling out:
Open one conversation with an image-capable model that supports conversation context. Gemini works well for this; other models with image generation and persistent context can work too. Paste your style guardrails as the first message — palette, perspective, aesthetic, what you don’t want. Then send your image prompts one at a time, in the same conversation, in the order you want the visual DNA to flow.
Don’t start a new session between images. Don’t summarize prior images in the next prompt. Trust the context window to do the carry-forward.
If an image isn’t quite right, ask for a revision in the same conversation rather than starting over. The model will adjust within the established style instead of regenerating fresh.
When you have all the images you need, the set is done. The cohesion you couldn’t have gotten from six separate API calls is now baked into the image files themselves.
A related workflow worth naming
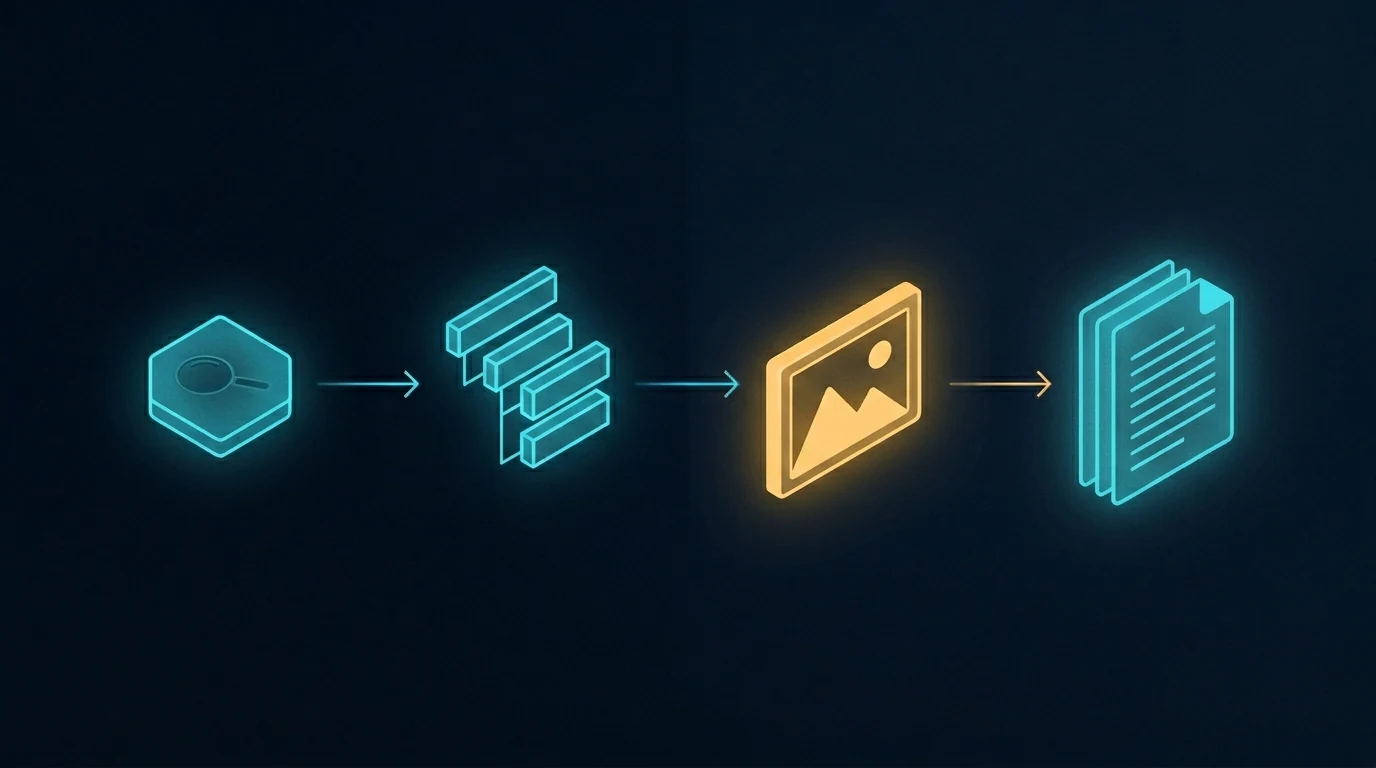
The image above shows a different rearrangement of the same pipeline — one where the image step jumps forward, ahead of the writing. The article gets written to fit the images, not the other way around. That’s a different topic with its own trade-offs, and we’re covering it in a forthcoming companion piece. For now, the relevant point is that whichever order you use, sequential generation is what makes coordinated multi-image content tractable. Without it, the activation energy of coordinating images is high enough that most teams default to one-off illustrations.
The reverse failure mode
The opposite mistake is also worth naming. Some teams, having discovered sequential generation, try to use it for everything. This wastes effort. A single featured image for a daily blog post doesn’t need to share visual DNA with any other image — it stands alone. Running it through a long conversation is overhead for no benefit.
The split is simple. If the images belong together, generate them together. If they stand alone, generate them alone.
When to use each method
Use sequential generation in one conversation context for:
- Pillar plus cluster article sets where the visual identity matters
- Multi-image articles where consistency across images is part of the message
- Flagship content where readers will perceive the image set as designed
- Brand-defining visual systems
- Anything where seeing two images side by side and noticing they belong together is part of the value
Use parallel generation across separate calls for:
- Single featured images on unrelated daily posts
- Site-wide batch fills where volume dominates
- Stock-style illustrations for routine content
- Background image work where nobody is looking at it twice
- Anything time-sensitive enough that the activation energy of opening a conversation isn’t worth it
The locked-together effect
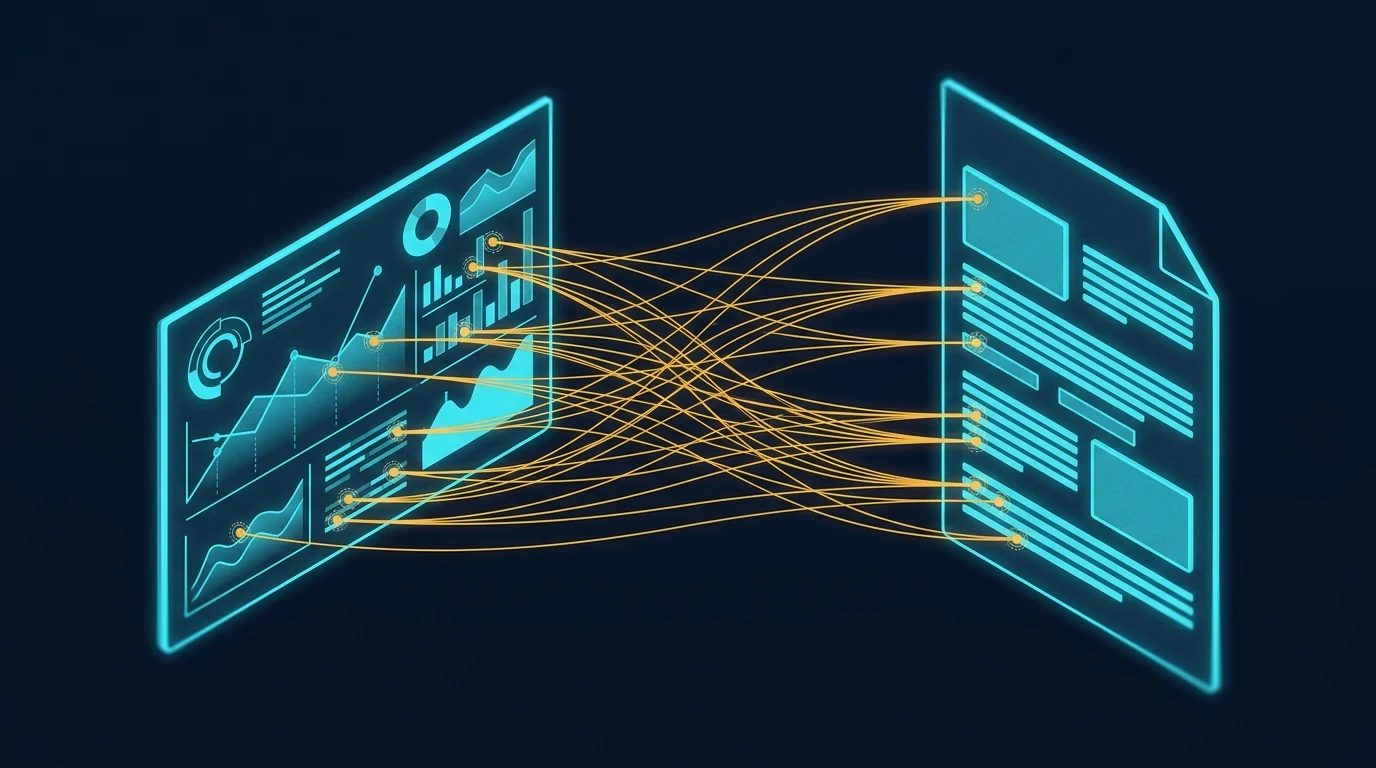
The image above shows what coherent visual sets enable in the actual reading experience. When the images in an article share visual DNA, a reader can reference back and forth between them — visual element here, paragraph there — without the cognitive friction of feeling like the images are coming from different worlds. Specific points in one image connect to specific points in another, or to specific points in the text, and the reader’s eye treats them as a system.
That’s what cohesion is worth. Not aesthetic prettiness in the abstract, but the reader’s ability to navigate the content as a unified whole instead of as a sequence of disconnected pieces.
Parallel generation can’t produce this effect reliably. Sequential generation can. The method is the difference.
The premise
The core insight is small enough to fit in a sentence: generate cohesive image sets in one conversation, generate independent images in parallel calls, and don’t conflate the two cases. Everything else in this article is unpacking that one observation.
The teams that get this right produce visual systems that look designed. The teams that get this wrong produce sets that look almost-designed — close enough that nobody complains, far enough that the work doesn’t quite land. The difference between those two outcomes is which workflow you use, and the workflow choice is essentially free once you know to make it.
This very article is a small proof of concept. The six images above were generated in a single Gemini conversation, in sequence. The visual DNA flows across all of them. None of that would have survived parallel generation. The choice was free; the result is visible.
Frequently asked questions
What is the difference between sequential and parallel image generation?
Sequential image generation creates multiple images inside a single conversation with an image-capable model, so each new image inherits visual DNA from the prior images in the same context window — palette, perspective, geometric language, and compositional rhythm carry forward automatically. Parallel image generation creates each image in a separate API call with no shared context, so each call is a cold start that follows style keywords but cannot inherit feel.
Why does conversation context matter for image generation?
When images are generated in one conversation, the model can see the prior images it generated and use them as anchors for the next image. This means visual specifications you set once are carried forward without you having to re-state them. The result is dramatically tighter cohesion than parallel API calls can produce, even when both methods use identical prompts.
When should I use sequential image generation instead of parallel calls?
Use sequential generation when the image set is part of the value proposition — pillar and cluster article sets, multi-image flagship articles, brand-defining visual systems, anything where readers will perceive the images as belonging to a designed whole. Use parallel generation for single featured images on unrelated daily posts, site-wide batch fills, stock-style illustrations, and routine content where volume matters more than coherence.
Does this method only work with Gemini?
No. The method works with any image-capable model that supports persistent conversation context — meaning the model can see prior turns in the same conversation and use them when generating new images. Gemini handles this well today. Other models with similar capabilities work just as well. The principle is about conversation context, not about a specific provider.
What is the “seam test” for image set cohesion?
The seam test asks whether your images need to feel like one project when seen at a glance — like five views of the same world rather than five separate illustrations. If yes, sequential generation is the right method. If the images can stand alone without referencing each other, parallel generation is faster and equally good. The split between volume work and premium work follows the seam test.
Can I mix sequential and parallel generation in the same project?
Yes, and it often makes sense. Generate the cohesive set sequentially for the article’s main illustrations, then use parallel generation for one-off support images, thumbnails, or social variants that don’t need to share DNA with the main set. The methods are tools, not ideologies. Match the method to the cohesion requirement of each image.








